WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv WARNING: You are using pip version 22.0.4; however, version 22.1 is available. You should consider upgrading via the '/opt/conda/bin/python -m pip install --upgrade pip' command.
Data Preparation with SageMaker Data Wrangler (Part 1)
aws
ml
sagemaker
A detailed guide on AWS SageMaker Data Wrangler to prepare data for machine learning models. This is a five parts series where we will prepare, import, explore, process, and export data using AWS Data Wrangler. You are reading Part 1:Prepare synthetic data and place it on multiple sources.

Enviornment
This notebook is prepared with Amazon SageMaker Studio using Python 3 (Data Science) Kernel and ml.t3.medium instance.
About
This is a detailed guide on using AWS SageMaker Data Wrangler service to prepare data for machine learning models. SageMaker Data Wrangler is a multipurpose tool with which you can * import data from multiple sources * explore data with visualizations * apply transformations * export data for ml training
This guide is divided into five parts * Part 1: Prepare synthetic data and place it on multiple sources (You are here) * Part 2: Import data from multiple sources using Data Wrangler * Part 3: Explore data with Data Wrangler visualizations * Part 4: Preprocess data using Data Wrangler * Part 5: Export data for ML training
Credits
Getting Started with Amazon SageMaker Studio book by Michael Hsieh. Michael Hsieh is a senior AI/machine learning (ML) solutions architect at Amazon Web Services. He creates and evangelizes for ML solutions centered around Amazon SageMaker. He also works with enterprise customers to advance their ML journeys.
Part 1: Prepare synthetic data and place it on multiple sources
Let’s prepare some dataset and place it on the S3 bucket and AWS Glue tables. Then we will use Data Wrangler to pull and join data from these two sources. The idea is to simulate some real project challenges where data is not coming from a single source but is distributed in multiple stores, and is in different formats. It is usually the preprocessing pipeline job to get data from these sources and join and preprocess it.
Data
Mobile operators have historical records on which customers ultimately ended up churning and which continued using the service. We can use this historical information to construct an ML model of one mobile operator’s churn using a process called training. After training the model, we can pass the profile information of an arbitrary customer (the same profile information that we used to train the model) to the model, and have the model predict whether this customer is going to churn. Of course, we expect the model to make mistakes. After all, predicting the future is a tricky business! But we’ll learn how to deal with prediction errors.
The dataset we use is publicly available and was mentioned in the book Discovering Knowledge in Data by Daniel T. Larose. It is attributed by the author to the University of California Irvine Repository of Machine Learning Datasets (Jafari-Marandi, R., Denton, J., Idris, A., Smith, B. K., & Keramati, A. (2020).
Preparation
download: s3://sagemaker-sample-files/datasets/tabular/synthetic/churn.txt to ./churn.txt| State | Account Length | Area Code | Phone | Int'l Plan | VMail Plan | VMail Message | Day Mins | Day Calls | Day Charge | Eve Mins | Eve Calls | Eve Charge | Night Mins | Night Calls | Night Charge | Intl Mins | Intl Calls | Intl Charge | CustServ Calls | Churn? | CustomerID | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | PA | 163 | 806 | 403-2562 | no | yes | 300 | 8.162204 | 3 | 7.579174 | 3.933035 | 4 | 6.508639 | 4.065759 | 100 | 5.111624 | 4.928160 | 6 | 5.673203 | 3 | True. | 0 |
| 1 | SC | 15 | 836 | 158-8416 | yes | no | 0 | 10.018993 | 4 | 4.226289 | 2.325005 | 0 | 9.972592 | 7.141040 | 200 | 6.436188 | 3.221748 | 6 | 2.559749 | 8 | False. | 1 |
| 2 | MO | 131 | 777 | 896-6253 | no | yes | 300 | 4.708490 | 3 | 4.768160 | 4.537466 | 3 | 4.566715 | 5.363235 | 100 | 5.142451 | 7.139023 | 2 | 6.254157 | 4 | False. | 2 |
| 3 | WY | 75 | 878 | 817-5729 | yes | yes | 700 | 1.268734 | 3 | 2.567642 | 2.528748 | 5 | 2.333624 | 3.773586 | 450 | 3.814413 | 2.245779 | 6 | 1.080692 | 6 | False. | 3 |
| 4 | WY | 146 | 878 | 450-4942 | yes | no | 0 | 2.696177 | 3 | 5.908916 | 6.015337 | 3 | 3.670408 | 3.751673 | 250 | 2.796812 | 6.905545 | 4 | 7.134343 | 6 | True. | 4 |
| 5 | VA | 83 | 866 | 454-9110 | no | no | 0 | 3.634776 | 7 | 4.804892 | 6.051944 | 5 | 5.278437 | 2.937880 | 300 | 4.817958 | 4.948816 | 4 | 5.135323 | 5 | False. | 5 |
| 6 | IN | 140 | 737 | 331-5751 | yes | no | 0 | 3.229420 | 4 | 3.165082 | 2.440153 | 8 | 0.264543 | 2.352274 | 300 | 3.869176 | 5.393439 | 4 | 1.784765 | 4 | False. | 6 |
| 7 | LA | 54 | 766 | 871-3612 | no | no | 0 | 0.567920 | 6 | 1.950098 | 4.507027 | 0 | 4.473086 | 0.688785 | 400 | 6.132137 | 5.012747 | 5 | 0.417421 | 8 | False. | 7 |
| 8 | MO | 195 | 777 | 249-5723 | yes | no | 0 | 5.811116 | 6 | 4.331065 | 8.104126 | 2 | 4.475034 | 4.208352 | 250 | 5.974575 | 4.750153 | 7 | 3.320311 | 7 | True. | 8 |
| 9 | AL | 104 | 657 | 767-7682 | yes | no | 0 | 2.714430 | 7 | 5.138669 | 8.529944 | 6 | 3.321121 | 2.342177 | 300 | 4.328966 | 3.433554 | 5 | 5.677058 | 4 | False. | 9 |
By modern standards, it’s a relatively small dataset, with only 5,000 records, where each record uses 21 attributes to describe the profile of a customer of an unknown US mobile operator. The attributes are:
State: the US state in which the customer resides, indicated by a two-letter abbreviation; for example, OH or NJAccount Length: the number of days that this account has been activeArea Code: the three-digit area code of the corresponding customer’s phone numberPhone: the remaining seven-digit phone numberInt’l Plan: whether the customer has an international calling plan: yes/noVMail Plan: whether the customer has a voice mail feature: yes/noVMail Message: the average number of voice mail messages per monthDay Mins: the total number of calling minutes used during the dayDay Calls: the total number of calls placed during the dayDay Charge: the billed cost of daytime callsEve Mins, Eve Calls, Eve Charge: the billed cost for calls placed during the eveningNight Mins, Night Calls, Night Charge: the billed cost for calls placed during nighttimeIntl Mins, Intl Calls, Intl Charge: the billed cost for international callsCustServ Calls: the number of calls placed to Customer ServiceChurn?: whether the customer left the service: true/false
The last attribute, Churn?, is known as the target attribute: the attribute that we want the ML model to predict. Because the target attribute is binary, our model will be performing binary prediction, also known as binary classification.
We have our dataset. Now we will split this dataset into three subsets * customer: customer data, and place it as a CSV file on the S3 bucket * account: accounts data, and place it as CSV on the same S3 bucket * utility: utility data, and place it as Glue tables
customer_columns = ['CustomerID', 'State', 'Area Code', 'Phone']
account_columns = ['CustomerID', 'Account Length', "Int'l Plan", 'VMail Plan', 'Churn?']
utility_columns = ['CustomerID', 'VMail Message', 'Day Mins', 'Day Calls', 'Day Charge',
'Eve Mins', 'Eve Calls', 'Eve Charge', 'Night Mins', 'Night Calls',
'Night Charge', 'Intl Mins', 'Intl Calls', 'Intl Charge', 'CustServ Calls']We will use the default bucket associated with our SageMaker session. You may use any other bucket with proper access permissions.
Next, we will use AWS Data Wrangler Python package (awswrangler) to create an AWS Glue database.
awswrangler is an open source Python library maintained by AWS team, as is defined as
An AWS Professional Service open source python initiative that extends the power of Pandas library to AWS connecting DataFrames and AWS data related services. Easy integration with Athena, Glue, Redshift, Timestream, OpenSearch, Neptune, QuickSight, Chime, CloudWatchLogs, DynamoDB, EMR, SecretManager, PostgreSQL, MySQL, SQLServer and S3 (Parquet, CSV, JSON and EXCEL).
You may read more about this library here * Documentation: https://aws-data-wrangler.readthedocs.io/en/stable/what.html * Github repo: https://github.com/awslabs/aws-data-wrangler
Please note that AWS SageMaker session needs some additional AWS Glue permissions to create a database. If you get an error while creating a Glue database in following steps then add those permissions.
Error: AccessDeniedException: An error occurred (AccessDeniedException) when calling the GetDatabase operation: User: arn:aws:sts::801598032724:assumed-role/AmazonSageMaker-ExecutionRole-20220516T161743/SageMaker is not authorized to perform: glue:GetDatabase on resource: arn:aws:glue:us-east-1:801598032724:database/telco_db because no identity-based policy allows the glue:GetDatabase action
Fix: Go to your SageMaker Execution Role and add permission AWSGlueConsoleFullAccess
##
import awswrangler as wr
# get all the existing Glue db list
databases = wr.catalog.databases()
# print existing db names
print("*** existing databases ***\n")
print(databases)
# if our db does not exist then create it
if db_name not in databases.values:
wr.catalog.create_database(db_name, description = 'Demo DB for telco churn dataset')
print("\n*** existing + new databases ***\n")
print(wr.catalog.databases())
else:
print(f"Database {db_name} already exists")*** existing databases ***
Database Description
0 sagemaker_data_wrangler
1 sagemaker_processing
*** existing + new databases ***
Database Description
0 sagemaker_data_wrangler
1 sagemaker_processing
2 telco_db Demo DB for telco churn datasetSimilarly you can go to AWS Glue console to see that the new database has been created.
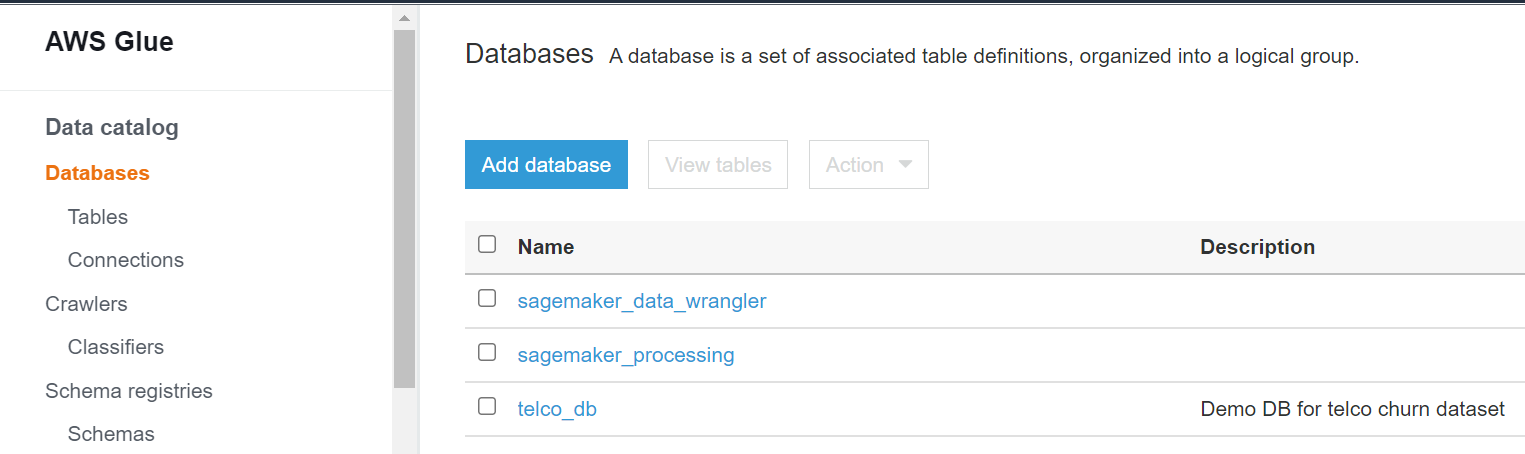
Now we will place the three data subsets into their respective locations.
suffix = ['customer_info', 'account_info', 'utility']
for i, columns in enumerate([customer_columns, account_columns, utility_columns]):
# get the data subset
df_tmp = df[columns]
# prepare filename and output path
fname = 'telco_churn_%s' % suffix[i]
outputpath = f's3://{bucket}/{prefix}/data/{fname}'
print(f"\n*** working on {suffix[i]}***")
print(f"filename: {fname}")
print(f"output path: {outputpath}")
if i > 1: # for utility
wr.s3.to_csv(
df=df_tmp,
path=outputpath,
dataset=True,
database=db_name, # Athena/Glue database
table=fname, # Athena/Glue table
index=False,
mode='overwrite')
else: # for customer and account
wr.s3.to_csv(
df=df_tmp,
path=f'{outputpath}.csv',
index=False)
*** working on customer_info***
filename: telco_churn_customer_info
output path: s3://sagemaker-us-east-1-801598032724/myblog/demo-customer-churn/data/telco_churn_customer_info
*** working on account_info***
filename: telco_churn_account_info
output path: s3://sagemaker-us-east-1-801598032724/myblog/demo-customer-churn/data/telco_churn_account_info
*** working on utility***
filename: telco_churn_utility
output path: s3://sagemaker-us-east-1-801598032724/myblog/demo-customer-churn/data/telco_churn_utilityWe can verify the uploaded data from the S3 bucket.
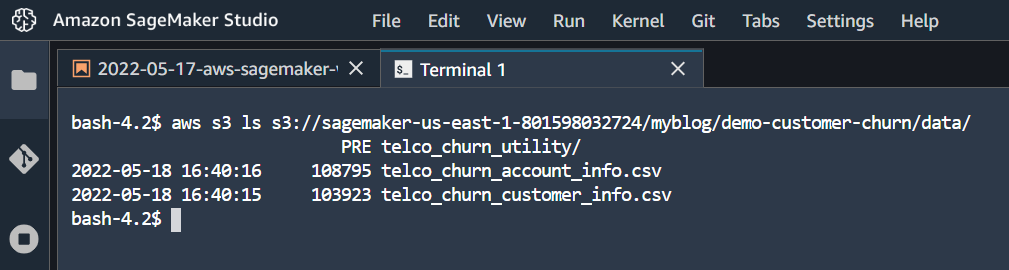
Similarly, from Glue console we can verify that the utility table has been created.

If you want to remain within the notebook and do the verification then that can also be done.
['s3://sagemaker-us-east-1-801598032724/myblog/demo-customer-churn/data/telco_churn_account_info.csv',
's3://sagemaker-us-east-1-801598032724/myblog/demo-customer-churn/data/telco_churn_customer_info.csv',
's3://sagemaker-us-east-1-801598032724/myblog/demo-customer-churn/data/telco_churn_utility/b4003acdf33e48ce989401e92146923c.csv']Summary
At this point we have our dataset ready in AWS S3 and Glue, and in the next part we will use AWS SageMaker Data Wrangler to import and join this data.