%%capture
!pip install --upgrade sagemaker
!pip install matplotlib
!pip install watermark
# 1. Get the latest version of SageMaker Python SDK. https://github.com/aws/sagemaker-python-sdk
# 2. Install matplotlib. https://github.com/matplotlib/matplotlib
# 3. Install watermark. An IPython magic extension for printing date and time stamps, version numbers, and hardware information. https://github.com/rasbt/watermarkBuild your own Generative AI Art Studio with Amazon SageMaker JumpStart
aws
ml
In this notebook, I demonstrate how to use the SageMaker Jumpstart to generate images from text using state-of-the-art Stable Diffusion models.

Credits
This notebook took inspiration from the AWS Machine Learning Blog post when they announced the availability of Stable Diffusion V1 and Stable Diffusion V2 models on SageMaker JumpStart. You can find the original post here Generate images from text with the stable diffusion model on Amazon SageMaker JumpStart.
Introduction
What Is Amazon SageMaker?
Amazon SageMaker is a fully managed machine learning service. With SageMaker, data scientists and developers can quickly and easily build and train machine learning models, and then directly deploy them into a production-ready hosted environment. It provides an integrated Jupyter authoring notebook instance for easy access to your data sources for exploration and analysis, so you don’t have to manage servers. It also provides common machine learning algorithms that are optimized to run efficiently against extremely large data in a distributed environment. With native support for bring-your-own-algorithms and frameworks, SageMaker offers flexible distributed training options that adjust to your specific workflows. You can deploy a model into a secure and scalable environment by launching it with a few clicks from SageMaker Studio or the SageMaker console.
Note
Amazon SageMaker introduction is taken from SageMaker Developer Guide. You may use Developer Guide for more details including Get Started with Amazon SageMaker.
What is SageMaker JumpStart?
SageMaker JumpStart is the machine learning (ML) hub of SageMaker that provides hundreds of built-in algorithms, pre-trained models, and end-to-end solution templates to help you quickly get started with ML. JumpStart also provides solution templates that set up infrastructure for common use cases, and executable example notebooks for machine learning with SageMaker.
Note
SageMaker JumpStart introduction is taken from SageMaker JumpStart Developer Guide. You may use Developer Guide for more details including Get Started and one-click, end-to-end Solution Templates for many common machine learning use cases.
What is Stable Diffusion?
Stable Diffusion is a text-to-image model that enables you to create photorealistic images from just a text prompt. A diffusion model trains by learning to remove noise that was added to a real image. This de-noising process generates a realistic image. These models can also generate images from text alone by conditioning the generation process on the text. For instance, Stable Diffusion is a latent diffusion where the model learns to recognize shapes in a pure noise image and gradually brings these shapes into focus if the shapes match the words in the input text.
How does JumpStart simplify it?
Training, deploying, and running inference on large models such as Stable Diffusion is often challenging. It includes issues such as CUDA being out of memory, the payload size limit being exceeded, and so on. JumpStart simplifies this process by providing ready-to-use scripts that have been robustly tested. Furthermore, it provides guidance on each step of the process, including the recommended instance types, how to select parameters to guide the image generation process, prompt engineering, etc. Moreover, you can deploy and run inference on any of the 80+ Diffusion models from JumpStart without having to write any piece of your own code.
Note
Stable Diffusion (SD) introduction is taken from Amazon JumpStart Text To Image notebook. For a more in-depth discussion on SD architecture and working, I suggest reading Jay Alammar The Illustrated Stable Diffusion guide.
Environment
This notebook is created with Amazon SageMaker Studio running on ml.t3.medium instance with Python 3 (Base Python 2.0) kernel.
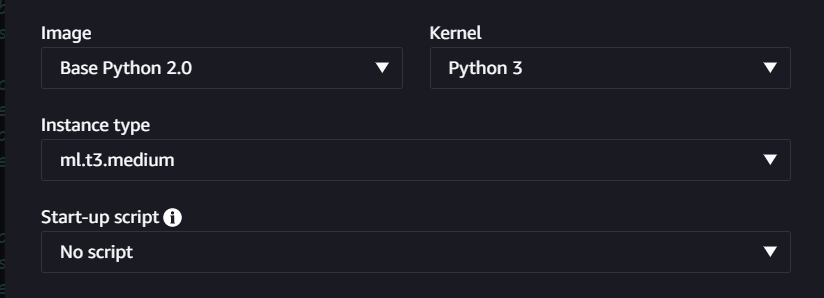
For model deployment and inference, I recommend using the ml.p3.2xlarge or ml.g4dn.2xlarge instance. I have relied on the ml.p3.2xlarge instance for this notebook. For generating multiple images per prompt, ml.g4dn.2xlarge can be slow, and you will get timeout errors as highlighted below.
Important
By default, both ml.p3.2xlarge and ml.g4dn.2xlarge may not be available in your AWS account. To get access, you need to generate a Request quota increase ticket from Service Quotas > AWS services > Amazon SageMaker > ml.p3.2xlarge for endpoint usage. A service request may take up to 24 hours to get approved.
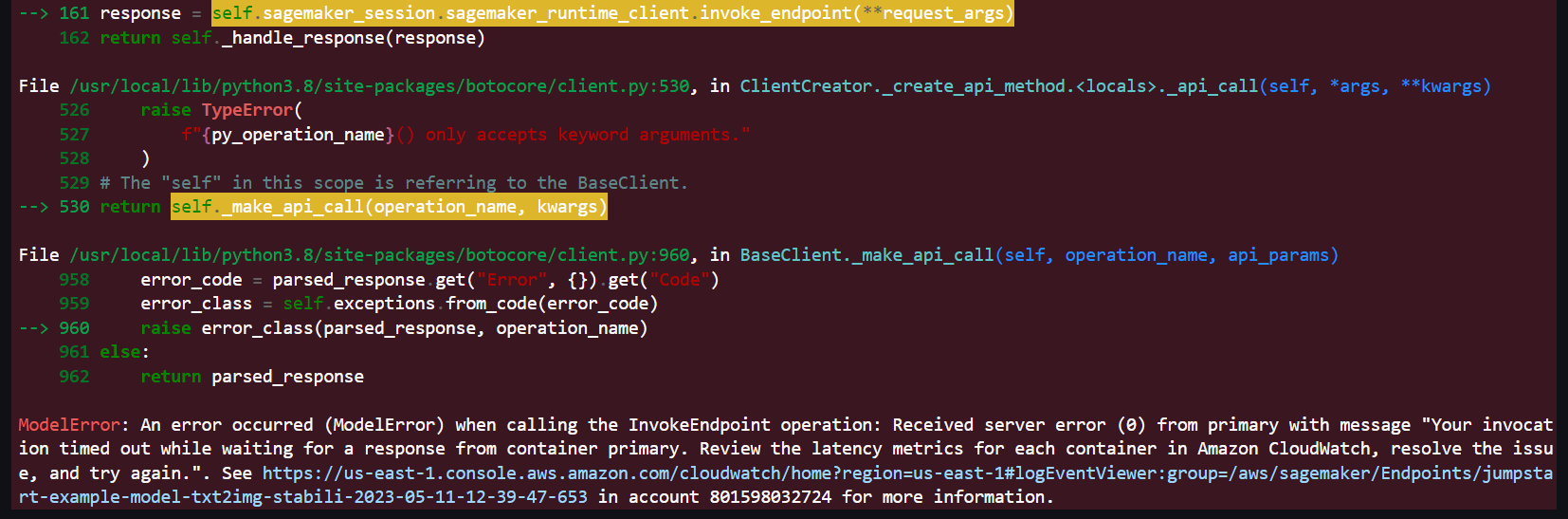
Tip
Why this timeout exception?
You get an API endpoint when you deploy a model into production using Amazon SageMaker hosting services. Your client applications use this API to get inferences from the model hosted at the specified endpoint. There is a 60 seconds hard limit on these API endpoints.
A customer’s model containers must respond to requests within 60 seconds. The model itself can have a maximum processing time of 60 seconds before responding to invocations. If your model is going to take 50-60 seconds of processing time, the SDK socket timeout should be set to be 70 seconds.
To read more about it, refer to the documentation SageMakerRuntime.Client.invoke_endpoint
What to do when your model requires more than 60 seconds for inference?
For such cases, AWS recommends using Amazon SageMaker Asynchronous Inference. This option is ideal for inferences with large payload sizes (up to 1GB) or long processing times (up to 15 minutes). To read more about it, use the following references.
Set up the environment
There are some initial steps required to execute this notebook. They mainly involve installing the needed packages and initializing the SageMaker session.
watermark extension is a great utility to expose packages, kernel, and hardware information. Though this is optional, and you may skip this step, it is a great way to report execution environment information and make it more transparent.
%watermark -v -m -p numpy,matplotlib,boto3,json,sagemaker
# watermark the notebook environment
# watermark step is optional. This is done to make the environment details more transpaentPython implementation: CPython
Python version : 3.8.12
IPython version : 8.12.0
numpy : 1.24.3
matplotlib: 3.7.1
boto3 : 1.26.111
json : 2.0.9
sagemaker : 2.153.0
Compiler : GCC 10.2.1 20210110
OS : Linux
Release : 4.14.311-233.529.amzn2.x86_64
Machine : x86_64
Processor :
CPU cores : 2
Architecture: 64bit
Next, we will initialize the SageMaker session. This session manages interactions with the Amazon SageMaker APIs and any other AWS services needed. It provides convenient methods for manipulating entities and resources that Amazon SageMaker uses, such as training jobs, endpoints, and input datasets in S3. AWS service calls are delegated to an underlying Boto3 session, which is initialized using the AWS configuration chain by default.
To read more about SageMaker Session refer to the documentation sagemaker.session.Session
Define functions to deploy models and get inference endpoints
In this section, we will define some functions that will make it easy for us to deploy JumpStart pre-trained models and get inference endpoints against them.
Show the code
from sagemaker import image_uris, model_uris
from sagemaker.model import Model
from sagemaker.predictor import Predictor
from sagemaker.utils import name_from_base
def get_model_endpoint(model_id, sagemaker_session, instance_type="ml.p3.2xlarge"):
"""Deploy the model on the provided instance type are return the inference endpoint"""
# Get the endpoint name from the provided 'model_id'
endpoint_name = name_from_base(f"jumpstart-example-{model_id}")
# recommended `inference_instance_type` are
# "ml.g4dn.2xlarge"
# "ml.g5.2xlarge"
# "ml.p3.2xlarge"
inference_instance_type = instance_type
# Retrieve the inference docker container uri.
# This is the base HuggingFace container image for the default model above.
deploy_image_uri = image_uris.retrieve(
region=None,
framework=None, # automatically inferred from model_id
image_scope="inference",
model_id=model_id,
model_version="*", # '*' means get the latest version
instance_type=inference_instance_type,
)
# Retrieve the model uri. This includes the pre-trained model and parameters as well as the inference scripts.
# This includes all dependencies and scripts for model loading, inference handling etc..
model_uri = model_uris.retrieve(
model_id=model_id, model_version="*", model_scope="inference"
)
# To increase the maximum response size from the endpoint.
# Response in our case will be generated images
env = {
"MMS_MAX_RESPONSE_SIZE": "20000000",
}
# Create the SageMaker model instance
model = Model(
image_uri=deploy_image_uri,
model_data=model_uri,
role=aws_role,
predictor_cls=Predictor,
name=endpoint_name,
env=env,
)
# Deploy the Model and return Inference endpoint. Note that we need to pass Predictor class when we deploy model through Model class,
# for being able to run inference through the sagemaker API.
return model.deploy(
initial_instance_count=1,
instance_type=inference_instance_type,
predictor_cls=Predictor,
endpoint_name=endpoint_name,
sagemaker_session=sagemaker_session,
)
def remove_model_endpoint(model_predictor):
"""Remove the model and deployed inference endpoint"""
model_predictor.delete_model()
model_predictor.delete_endpoint()Define functions to query endpoints and display results
In the next section, we will define some functions that we will use to query the inference endpoint and display the results.
Show the code
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from io import BytesIO
import base64
import json
import re
import os
# Define a path to save the generated images
image_path = "./images/2023-05-10-amazon-jumpstart-text2img-stablediffusion/generated/"
os.makedirs(image_path, exist_ok=True) # create folder if not present
def display_and_save_img(image, filename):
"""Display and save the hallucinated image."""
plt.figure(figsize=(7, 7), frameon=False)
plt.imshow(np.array(image))
plt.axis("off")
plt.savefig(
image_path + filename, bbox_inches="tight", transparent=True, pad_inches=0
) # comment it to NOT save generated images
plt.show()
def query_endpoint_with_json_payload(model_predictor, payload, content_type, accept):
"""Query the model predictor with json payload."""
encoded_payload = json.dumps(payload).encode("utf-8")
query_response = model_predictor.predict(
encoded_payload, {"ContentType": content_type, "Accept": accept,},
)
return query_response
def display_encoded_images(generated_images, prompt):
"""Decode the images and convert to RGB format and display
Args:
generated_images: are a list of jpeg images as bytes with b64 encoding.
prompt: text string used to generate the images
"""
for count, generated_image in enumerate(generated_images):
generated_image_decoded = BytesIO(base64.b64decode(generated_image.encode()))
generated_image_rgb = Image.open(generated_image_decoded).convert("RGB")
# prepare filename to store the image from the prompt
temp = re.sub(
r"[^a-zA-Z0-9\s]+", "", prompt
) # remove special chars from prompt
temp = temp.replace(" ", "-") # turn spaces to '-'
temp = temp[:50] # limit the lenght of string upto 100 chars
filename = (
temp + str(count) + ".jpg"
) # add count and extension to the image name
# display the generated image
display_and_save_img(generated_image_rgb, filename)
def parse_response_multiple_images(query_response):
"""Parse response and return generated image and the prompt"""
response_dict = json.loads(query_response)
return response_dict["generated_images"], response_dict["prompt"]
def query_model_and_display(payload, model_predictor):
query_response = query_endpoint_with_json_payload(
model_predictor, payload, "application/json", "application/json;jpeg"
)
generated_images, prompt = parse_response_multiple_images(query_response)
display_encoded_images(generated_images, prompt)Supported Inference parameters
We have to pass along some advanced parameters in the request to get inferences from the model API. These include
prompt: prompt to guide the image generation. It must be specified and can be a string or a list of strings.width: width of the generated image. If specified, it must be a positive integer divisible by 8.height: height of the generated image. If specified, it must be a positive integer divisible by 8.num_inference_steps: Number of denoising steps during image generation. More steps lead to a higher-quality image. If specified, it must be a positive integer.guidance_scale: Higher guidance scale results in an image closely related to the prompt at the expense of image quality. If specified, it must be a float. guidance_scale<=1 is ignored.negative_prompt: guide image generation against this prompt. If specified, it must be a string or a list of strings used with guidance_scale. If guidance_scale is disabled, this is also disabled. Moreover, if a prompt is a list of strings, then negative_prompt must also be a list of strings.num_images_per_prompt: number of images returned per prompt. If specified, it must be a positive integer.seed: Fix the randomized state for reproducibility. If specified, it must be an integer.
An example request payload is provided below. The effect of these parameters will become apparent when we generate images using them.
payload = {
"prompt": "a portrait of a man",
"negative_prompt": "beard"
"width": 512,
"height": 512,
"num_images_per_prompt": 1,
"num_inference_steps": 50,
"guidance_scale": 7.5,
"seed": 1,
}
Tip
prompt and negative_prompt: Stable Diffusion models are not good at understanding negative words ‘without’, ‘except’, ‘exclude’, ‘not’ etc in the prompt statement. For example, the prompt “a portrait of a man without a beard” may still generate an image of a man with a beard. However, including “negative_promt” with the word “beard” has much more influence on the model.height and width: The model often performs best when the generated image has dimensions similar to the training data dimension used for model training. It is recommended to read about the model to get the correct dimensions.num_images_per_prompt: From experience, a number between 1 and 5 works best for real-time inference endpoint.num_inference_steps: When experimenting with prompts, I tend to keep the “inference_steps” under 50. At 20, you will get a black-and-white image but get some idea of the image being produced. If I find an output with fine patterns, I try higher inference_steps between 100 and 150 to improve the quality further.
Select SageMaker pre-trained Diffusion model and Prompt Engineering
Model selection
SageMaker JumpStart provides many pre-trained models. Use the following link to search and select the correct Model ID. Built-in Algorithms with pre-trained Model Table. We are only interested in text-to-image models, and we can filter them using txt2img string in the search bar.
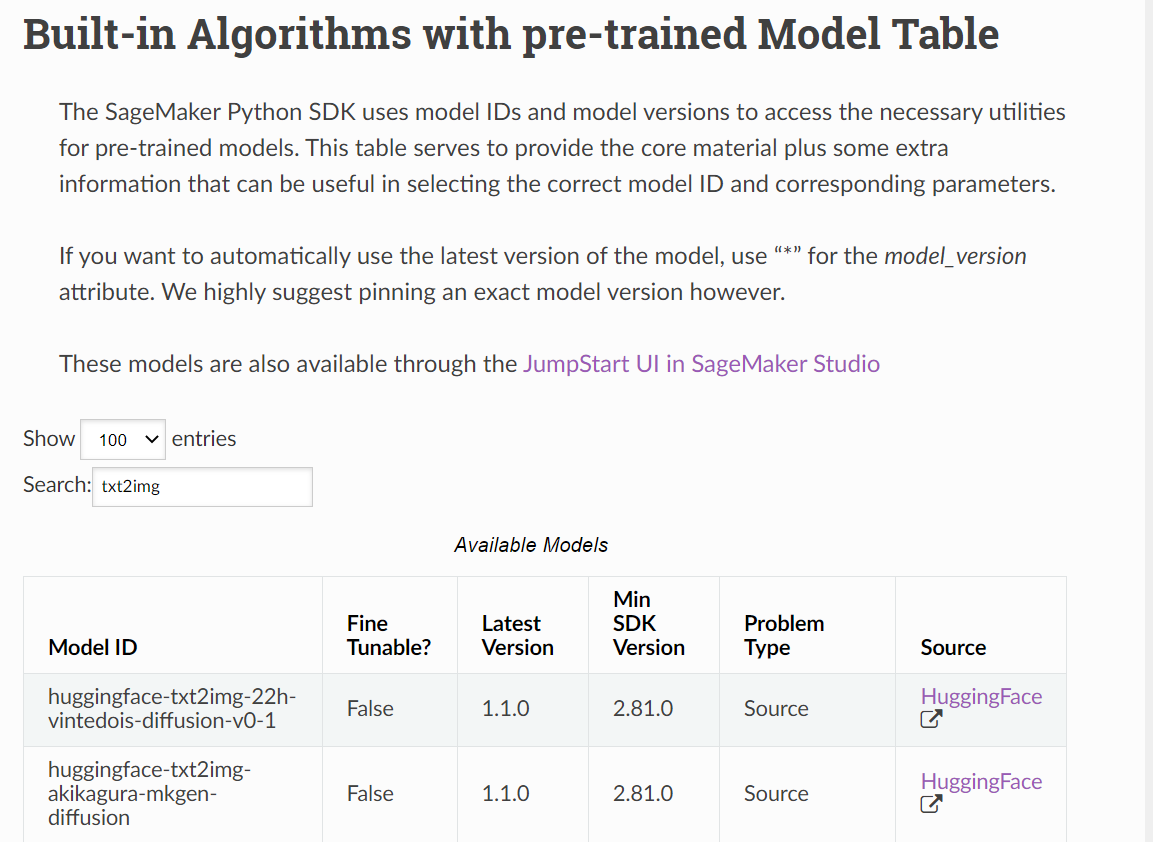
At the time of writing this notebook, 86 txt2img models are available on JumpStart. We may use any of them to generate the images. I have selected a few from them that are the more well-known. However, you are welcome to experiment with anyone of them. Following in the list of the models that we will use in the later part of this notebook.
Prompt engineering
Writing a good prompt can be an art. Predicting whether a particular prompt will yield a satisfactory image with a given model is often difficult. However, specific templates have been observed to work. Broadly, a prompt can be roughly broken down into three pieces:
- Type of image (photograph/sketch/painting, etc.)
- Description (subject/object/environment/scene, etc.)
- The style of the image (realistic/artistic/type of art, etc.)
You can change each of the three parts individually to generate variations of an image. Adjectives have been known to play a significant role in the image-generation process. Also, adding more details about the scene helps in the generation process. Here are some suggestions that you may follow to generate good prompts.
- To generate a realistic image, you can use phrases such as “a photo of,” “a photograph of,” “realistic,” or “hyper-realistic.”
- To generate images by artists, you can use phrases like “by Pablo Picasso,” “oil painting by Rembrandt,” “landscape art by Frederic Edwin Church,” or “pencil drawing by Albrecht Dürer.”
- You can combine different artists as well. For example, to generate artistic images by category, you can add the art category in the prompt such as “lion on a beach, abstract.”
- Some other types include “oil painting,” “pencil drawing, “pop art,” “digital art,” “anime,” “cartoon,” “futurism,” “watercolor,” “manga,” etc.
- You can also include details such as lighting or camera lenses such as 35mm wide lens or 85mm wide lens, and information on the framing (portrait/landscape/close up, etc.).
Tip
The above concise prompt engineering outline is taken from AWS Blog Post. For a more in-depth discussion and techniques to write good prompts, you may consult below resources.
- Stable Diffusion Art: a definitive prompt guide. An excellent beginner-level guide.
- Best Stable Diffusion Negative Prompt List To Use. It highlights techniques to improve results by using negative prompts.
- OpenArt.ai Prompt Book. A very detailed guide covering many techniques and areas.
Stable Diffusion v2-1
Let’s get our first model up and running stable-diffusion-2-1.
model_id = "model-txt2img-stabilityai-stable-diffusion-v2-1-base"
model_predictor = get_model_endpoint(model_id, sagemaker_session)---------!This base model is trained from scratch and can be applied to various use cases. However, to use this model, it is also important to understand some of the limitations.
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly
- The model was trained mainly with English captions and will not work as well in other languages
Realistic people
Let’s see how good is this model to generate real people images.
Show the code
prompt = "photo of young woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, ultra quality, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K UHD, highly detailed glossy eyes, high detailed skin, skin pores"
negative_prompt = "disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w"
payload = {
"prompt": prompt,
"negative_prompt": negative_prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 5,
"num_inference_steps": 50,
"guidance_scale": 7.5,
"seed": 1,
}
query_model_and_display(payload, model_predictor)




The model can generate images of faces with good symmetry but still struggles with hands and fingers. This is visible in images 3 and 5, where the fingers are distorted. Otherwise, it was able to capture the instructions from the prompt.
- photo of a young woman
- highlight hair
- sitting outside the restaurant
- wearing dress
Let’s try another prompt; this time, we will focus more on the body shape, parts, and aesthetics.
The results could be better, again highlighting that the Stable Diffusion v2.1 model still needs to improve at generating proper people faces and shapes.
Show the code
prompt = "sitting on green grass, bodybuilder posing, bodycam footage, man esthete with disgust face, overlooking a dark street, black and white photograph, sitting on a bench, dirty concrete wall, very sexy outfit, perfect face mode, sport photography, black business suit"
negative_prompt = "disfigured, ugly, bad"
payload = {
"prompt": prompt,
"negative_prompt": negative_prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 5,
"num_inference_steps": 50,
"guidance_scale": 7.5,
"seed": 1,
}
query_model_and_display(payload, model_predictor)




Architecture
Okay, we have seen that model struggles with depicting accurate body shapes. So let’s try something more complex and see how well the model understands building shapes and architectures.
Show the code
prompt = "A Hyperrealistic photograph of Italian architectural modern home in Italy, lens flares, cinematic, hdri, matte painting, concept art, celestial, soft render, highly detailed, octane render, architectural HD, HQ, 4k, 8k"
payload = {
"prompt": prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 5,
"num_inference_steps": 50,
"guidance_scale": 7.5,
"seed": 1,
}
query_model_and_display(payload, model_predictor)




These are very impressive results. The model is adept at understanding how modern buildings should look like. It can intelligently place windows, balconies, chairs, trees, shadows, and even reflections at appropriate locations. The design is also modern, meaning it follows the instructions well.
Let’s try another difficult prompt focusing on a city’s complex geometry and formations.
Show the code
prompt = "A beautiful digital illustration of BARCELONA, 4k, crystal clear, ultra HD, high definition, detailed, trending in artstation, fantasy"
payload = {
"prompt": prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 120,
"guidance_scale": 7.5,
"seed": 1,
}
query_model_and_display(payload, model_predictor)


The results are pretty good. The model can understand that structures at the front are expansive, and those at the far back slowly decreases in size. It also understands that roads run through and divides a typical city layout. The last image is impressive, containing a green belt having trees in the center. After that, there is a road busy with vehicles. And then, at the peripheries, there are building with intricate layouts.
Abstract art and styles
Let’s move to abstract art, styles, and artists and see how well the model portrays them.
Show the code
prompt = "A surreal 3D render of a cityscape with twisted buildings, upside-down structures, and floating objects, creating a dreamlike and disorienting atmosphere, by Simon Stålenhag"
payload = {
"prompt": prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 5,
"num_inference_steps": 50,
"guidance_scale": 7.5,
"seed": 1,
}
query_model_and_display(payload, model_predictor)




“Twisted upside-down buildings and floating objects” is very unusual, and hard to imagine what such a world would look like. But it is not difficult for the model to produce it. So let’s try some more prompts.
Show the code
prompt = "A futuristic space station orbiting a distant planet, with sleek design and advanced technology visible through the windows, Nuremberg Chronicle, 1493, Liber Chronicarum, Michael Wolgemut, detailed archtitecture"
negative_prompt = "writings, ugly, bad, immature, anime, b&w, lines, latin"
payload = {
"prompt": prompt,
"negative_prompt": negative_prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 50,
"guidance_scale": 7.5,
"seed": 1,
}
query_model_and_display(payload, model_predictor)


Show the code
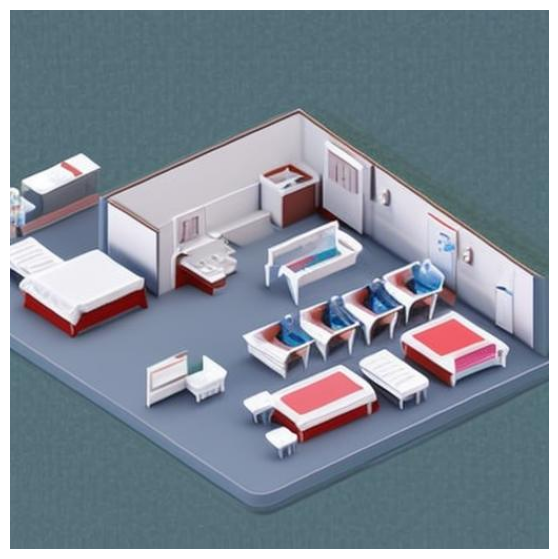
prompt = "Realistic 3D render of an isometric hospital in a low poly art style, medical workers, doctors, nurses, patients, beds and equipment."
payload = {
"prompt": prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 50,
"guidance_scale": 7.5,
"seed": 1,
}
query_model_and_display(payload, model_predictor)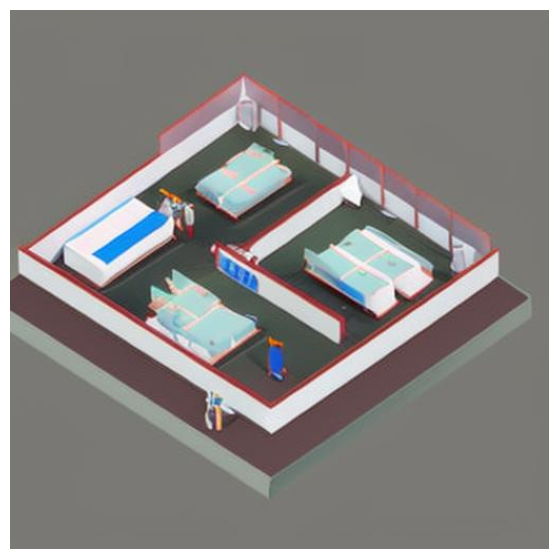

Landscapes
Let’s move to a more natural setting. The model can generate beautiful scenes involving meadows, wildlands, mountains, rivers, etc. The depth and details in the results are remarkable. Some prompts that I tried are provided here.
Show the code
prompt = "The green idyllic Arcadian prairie with sheep by Thomas Cole, Breath-taking digital painting with placid colors, amazing art, artstation 3, cottagecore."
payload = {
"prompt": prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 120,
"guidance_scale": 7.5,
"seed": 1,
}
query_model_and_display(payload, model_predictor)


Prompt
Show the code
prompt = "A beautiful castle beside a waterfall in the woods, by Josef Thoma, matte painting, trending on artstation HQ, full view"
payload = {
"prompt": prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 120,
"guidance_scale": 7.5,
"seed": 1,
}
query_model_and_display(payload, model_predictor)


Portraits and paintings
I also tried generating portraits and paintings of imaginative scenarios. Stable Diffusion is again very good at it. But similar to its limitations in creating accurate human body shapes, it struggles with them in paintings.
Show the code
prompt = "A painting of a pirate ship in the ocean, a digital painting, renaissance, color study, portrait, castle, three masts, davinci, whole page illustration, small boat"
negative_prompt = "logos, icons, writings, description"
payload = {
"prompt": prompt,
"negative_prompt": negative_prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 50,
"guidance_scale": 7.5,
"seed": 1,
}
query_model_and_display(payload, model_predictor)


Show the code
prompt = "Complex detailed medieval painting of a fantasy medieval cleric woman walking through a field of flowers, cleric wearing a tiara and a ornate embroidered hooded cloak, bright blue eyes, sharp focus, close shot, long blonde hair, high contrast, low saturation, lush flower field and clouds background, backlighting"
payload = {
"prompt": prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 120,
"guidance_scale": 7.5,
"seed": 1,
}
query_model_and_display(payload, model_predictor)


Please delete the model endpoint once it is no longer required to avoid unforeseen costs.
Tip
If your notebook kernel has crashed, manually delete the model endpoint by going to SageMaker > Inference > Endpoints. Make sure that you are in the right region in the Management Console. 
PromptHero Openjourney
Besides the Stable Diffusion base models, people have also released models with unique styles and tastes. One such model is OpenJourney. Openjourney is based on Stable Diffusion v1.5 but fine-tuned with many Midjourney images. The result is a model capable of generating very detailed and colorful photos. But to invoke the model’s unique style, we must append the prompt with the text modern-v4 style.
Let’s get this model up and running.
model_id = "huggingface-txt2img-prompthero-openjourney"
model_predictor = get_model_endpoint(model_id, sagemaker_session) ---------!Realistic people and portraits
Remember that this OpenJourney model is based on an older version of stable diffusion, but I found it equally good at generating faces and body shapes with acceptable symmetry.
Show the code
prompt = "mdjrny-v4 style old, female robot, metal, rust, wisible wires, destroyed, sad, dark, dirty, looking at viewer, portrait, photography, detailed skin, realistic, photo-realistic, 8k, highly detailed, full length frame, High detail RAW color art, piercing, diffused soft lighting, shallow depth of field, sharp focus, hyperrealism, cinematic lighting"
negative_prompt = "logo, CGI, 3d, lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck, username, watermark, signature"
payload = {
"prompt": prompt,
"negative_prompt": negative_prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 120,
"guidance_scale": 14,
"seed": 1,
}
query_model_and_display(payload, model_predictor)
# https://prompthero.com/prompt/4c1a987fec7


Show the code
prompt = "mdjrny-v4 style portrait photograph of Madison Beer as Pocahontas, young beautiful native american woman, perfect symmetrical face, feather jewelry, traditional handmade dress, armed female hunter warrior, wild west environment, Utah landscape, ultra realistic, concept art, elegant, intricate, highly detailed, depth of field, professionally color graded, 8k, art by artgerm and greg rutkowski and alphonse mucha"
negative_prompt = "backlight, dark face, white fur, gold fabric, cropped head, out of frame, deformed, cripple, ugly, additional arms, additional legs, additional head, two heads, multiple people, group of people"
payload = {
"prompt": prompt,
"negative_prompt": negative_prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 120,
"guidance_scale": 14,
"seed": 1,
}
query_model_and_display(payload, model_predictor)
# https://prompthero.com/prompt/d4f36f0dcdf


Show the code
prompt = "mdjrny-v4 style Incredibly detailed technical diagram of the profile of a woman with the top and back of her head split into complex geometric shapes and flowers growing from the shapes, Chiaroscuro lighting, fine intricate details"
negative_prompt = "long neck, skinny"
payload = {
"prompt": prompt,
"negative_prompt": negative_prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 120,
"guidance_scale": 14,
"seed": 1,
}
query_model_and_display(payload, model_predictor)
# https://prompthero.com/prompt/0c8536f3b23


Fairy Landscapes
You can also create very detailed and colorful photos of landscapes.
Show the code
prompt = "mdjrny-v4 style painting of a fairy forest, dream light, full of colors, mushroom tree, dim light, super detailed, unreal engine 5, hdr, 12k, by Vincent Van Goth"
payload = {
"prompt": prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 120,
"guidance_scale": 14,
"seed": 1,
}
query_model_and_display(payload, model_predictor)
# https://prompthero.com/prompt/19c0ad9cac1


Other digital art prompts
Some other prompt examples where the results are very impressive.
Show the code
prompt = "mdjrny-v4 style little dragon staring at magic spell book sitting on a table in the catacombs, hypermaximalist, insanely detailed and intricate, octane render, unreal engine, 8k, by greg rutkowski and Peter Mohrbacher and magali villeneuve"
payload = {
"prompt": prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 120,
"guidance_scale": 14,
"seed": 1,
}
query_model_and_display(payload, model_predictor)
# https://prompthero.com/prompt/63c7ed7865f


Show the code
prompt = "mdjrny-v4 style, magic spell book sitting on a table in the catacombs, hypermaximalist, insanely detailed and intricate, octane render, unreal engine, 8k, by greg rutkowski and Peter Mohrbacher and magali villeneuve"
payload = {
"prompt": prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 120,
"guidance_scale": 14,
"seed": 1,
}
query_model_and_display(payload, model_predictor)
# https://prompthero.com/prompt/4c1a987fec7


FantasyAI Anything V4.0
anything-v4.0 is another model with a particular style. It is also based on Stable Diffusion and is good at producing high-quality, highly detailed anime styles with just a few prompts.
Let’s get this model up and running.
model_id = "huggingface-txt2img-andite-anything-v4-0"
model_predictor = get_model_endpoint(model_id, sagemaker_session)---------!Realistic people
I used a simple prompt to get a portrait of a casual boy sitting in the coffee shop. From the results, you can see that it has a notable anime and manga taste. In addition, the boy’s eyes, hairstyle, clothes, and lighting all represent anime fashion.
Show the code



Let’s also try the same prompt we used to generate portraits of a young woman. But this time, all the generated images are in anime style.
Show the code
prompt = "photo of young woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, ultra quality, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K UHD, highly detailed glossy eyes, high detailed skin, skin pores"
negative_prompt = "disfigured, ugly, bad, immature, cartoon, anime, 3d, painting, b&w"
payload = {
"prompt": prompt,
"negative_prompt": negative_prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 120,
"guidance_scale": 7.5,
"seed": 1,
}
query_model_and_display(payload, model_predictor)


Warning
I have found that “anything-v4.0” model has a tendency to generate nude images. It could be because their creators have also used such images while finetuning the model. You have to rely on the negative prompt to restrict the model from generating such images.
Landscapes
Let’s also try our castle prompt. Again the generative images are representative of anime and manga styles.
Show the code
prompt = "A beautiful castle beside a waterfall in the woods, by Josef Thoma, matte painting, trending on artstation HQ"
payload = {
"prompt": prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 120,
"guidance_scale": 7.5,
"seed": 1,
}
query_model_and_display(payload, model_predictor)


Mo Di Diffusion
mo-di-diffusion is another model good at expressing Disney animation studio style. It is based on Stable Diffusion 1.5 and fine-tuned on screenshots from Disney animation studio. However, users must use the tokens modern disney style in the prompts to get the desired effect.
model_id = "huggingface-txt2img-nitrosocke-mo-di-diffusion"
model_predictor = get_model_endpoint(model_id, sagemaker_session)----------!Realistic people
Let’s start with our same “young boy in a coffee shop” prompt. This time the young boy is an attractive youthful adult characteristic of the Disney Animation world. The generated photographs have a very close resemblance to Kristoff from Frozen or Tadashi from Big Hero 6.
Show the code



The same is the case with a photo of young women. They remind me of Princess Moana from Disney World. But, unfortunately, the last image is distorted because MoDi is based on Stable Diffusion, which has these inherent limitations.
Show the code
prompt = "modern disney style photo of young woman, highlight hair, sitting outside restaurant, wearing dress, rim lighting, studio lighting, looking at the camera, dslr, ultra quality, sharp focus, tack sharp, dof, film grain, Fujifilm XT3, crystal clear, 8K UHD, highly detailed glossy eyes, high detailed skin, skin pores"
negative_prompt = "disfigured, ugly, bad, immature, crowd, people"
payload = {
"prompt": prompt,
"negative_prompt": negative_prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 120,
"guidance_scale": 7.5,
"seed": 1,
}
query_model_and_display(payload, model_predictor)


Landscapes and architectures
I have also tried generating landscapes and building architectures. Both cases have a heavy touch of Disney World animation style.
Show the code
prompt = "modern disney style A beautiful castle beside a waterfall in the woods, by Josef Thoma, matte painting, trending on artstation HQ"
payload = {
"prompt": prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 120,
"guidance_scale": 7.5,
"seed": 1,
}
query_model_and_display(payload, model_predictor)


Show the code
prompt = "modern disney style A Hyperrealistic photograph of Italian architectural modern home in Italy, lens flares, cinematic, hdri, matte painting, concept art, celestial, soft render, highly detailed, octane render, architectural HD, HQ, 4k, 8k"
payload = {
"prompt": prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 120,
"guidance_scale": 7.5,
"seed": 1,
}
query_model_and_display(payload, model_predictor)


Inkpunk Diffusion
Our last model to try is Inkpunk-Diffusion. It is also based on Stable Diffusion and fine-tuned for “Inky” and “Punky” styles. We have to use nvinkpunk in our prompts to summon this style. If you find that the InkPunk style is very dominating in the outcomes, then try experimenting without this token to get a lighter version of this style.
Let’s get this model up and running.
model_id = "huggingface-txt2img-envvi-inkpunk-diffusion"
model_predictor = get_model_endpoint(model_id, sagemaker_session)----------!Realistic people and portraits
I asked for a “medieval cleric woman”. In the InkPunk world, the lady turned out to be a super-rocky astro-woman from the century 2100. But the style is fantastic.
Show the code
prompt = "nvinkpunk Complex detailed painting of a fantasy medieval cleric woman walking through a field of flowers by rembrandt, cleric wearing a tiara and a ornate embroidered hooded cloak, bright blue eyes, evocative, sharp focus, close shot, long blonde hair, high contrast, low saturation, lush flower field and clouds background, backlighting."
payload = {
"prompt": prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 120,
"guidance_scale": 7.5,
"seed": 1,
}
query_model_and_display(payload, model_predictor)


Landscapes and architectures
Show the code
prompt = "nvinkpunk A Hyperrealistic photograph of Italian architectural modern home in Italy, lens flares, cinematic, hdri, matte painting, concept art, celestial, soft render, highly detailed, octane render, architectural HD, HQ, 4k, 8k"
payload = {
"prompt": prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 120,
"guidance_scale": 7.5,
"seed": 1,
}
query_model_and_display(payload, model_predictor)


Other digital art prompts
Show the code
prompt = "nvinkpunk bomb diffuser robot with assault rifle strapped to the top, killer robot"
payload = {
"prompt": prompt,
"width": 512,
"height": 512,
"num_images_per_prompt": 3,
"num_inference_steps": 120,
"guidance_scale": 7.5,
"seed": 1,
}
query_model_and_display(payload, model_predictor)
# https://prompthero.com/prompt/67bc77c123f


Show the code



Show the code


