aws-cli/1.25.27 Python/3.7.10 Linux/4.14.281-212.502.amzn2.x86_64 botocore/1.27.27Building a Feature Repository with SageMaker Feature Store
aws
ml
sagemaker
This notebook demonstrates how to build a central feature repository using Amazon SageMaker Feature Store. Feature Store is used to store, retrieve, and share machine learning features.

Introduction
Amazon SageMaker Feature Store is a fully managed, purpose-built repository to store, share, and manage features for machine learning (ML) models. Features are inputs to ML models used during training and inference. For example, in an application that recommends a music playlist, features could include song ratings, listening duration, and listener demographics. Features are used repeatedly by multiple teams and feature quality is critical to ensure a highly accurate model. Also, when features used to train models offline in batch are made available for real-time inference, it’s hard to keep the two feature stores synchronized. SageMaker Feature Store provides a secured and unified store for feature use across the ML lifecycle.
https://aws.amazon.com/sagemaker/feature-store/
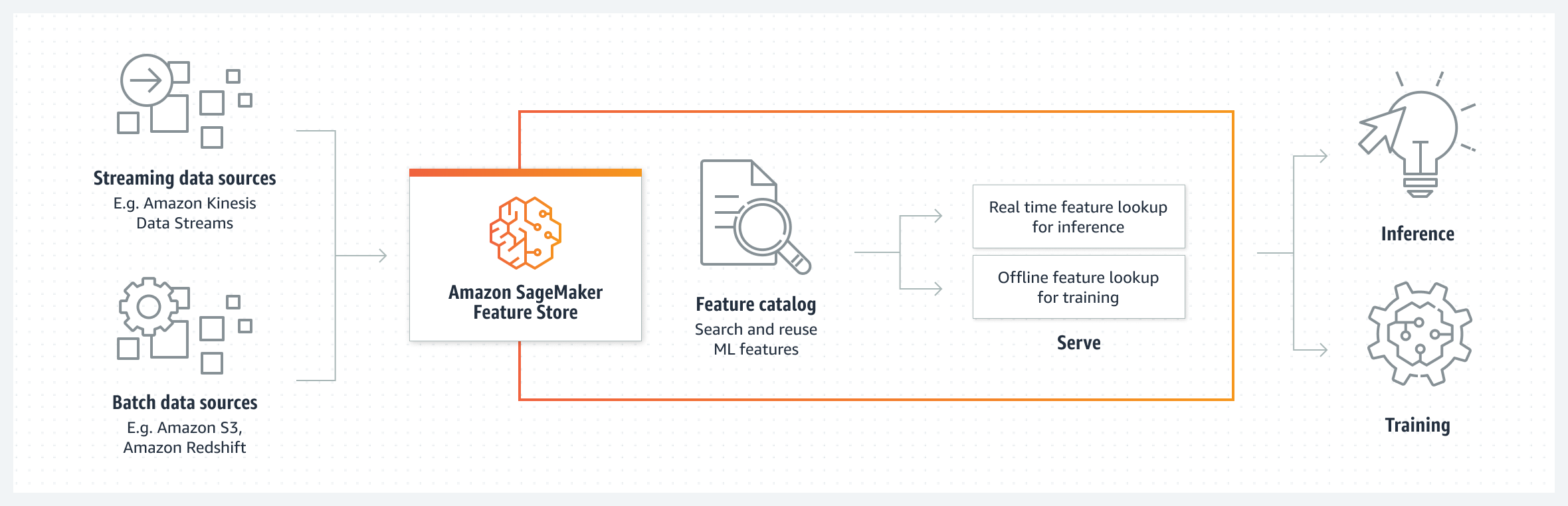
Environment
This notebook is prepared using Amazon SageMaker studio using Python 3 (Data Science) kernel running on ml.t3.medium instance.
Dataset used for this notebook
We will use a publically available bank marketing dataset. The data is related to direct marketing campaigns of a Portuguese banking institution. The marketing campaigns were based on phone calls. Often, more than one contact with the same client was required to access if the product (bank term deposit) would be (‘yes’) or not (‘no’) subscribed.
Data source
[Moro et al., 2014] S. Moro, P. Cortez and P. Rita. A Data-Driven Approach to Predict the Success of Bank Telemarketing. Decision Support Systems, Elsevier, 62:22-31, June 2014
Data link
UCI Machine Learning Repository: https://archive.ics.uci.edu/ml/datasets/bank+marketing. Dataset has multiple files. we will use bank-additional-full.csv file that has all examples (41188) and 20 inputs, ordered by date.
Data classification goal/target
The classification goal is to predict if the client will subscribe (yes/no) a term deposit (variable y)
Data attributes information
Input variables
attributes from bank client data 1. age (numeric) 2. job : type of job (categorical: ‘admin.’, ‘blue-collar’, ‘entrepreneur’, ‘housemaid’, ‘management’, ‘retired’, ‘self-employed’, ‘services’,‘student’, ‘technician’, ‘unemployed’, ‘unknown’) 3. marital : marital status (categorical: ‘divorced’, ‘married’, ‘single’, ‘unknown’; note: ‘divorced’ means divorced or widowed) 4. education (categorical: ‘basic.4y’, ‘basic.6y’, ‘basic.9y’, ‘high.school’, ‘illiterate’,‘professional.course’, ‘university.degree’,‘unknown’) 5. default: has credit in default? (categorical: ‘no’,‘yes’,‘unknown’) 6. housing: has housing loan? (categorical: ‘no’,‘yes’,‘unknown’) 7. loan: has personal loan? (categorical: ‘no’,‘yes’,‘unknown’)
attributes related with the last contact of the current campaign
- contact: contact communication type (categorical: ‘cellular’,‘telephone’)
- month: last contact month of year (categorical: ‘jan’, ‘feb’, ‘mar’, …, ‘nov’, ‘dec’)
- day_of_week: last contact day of the week (categorical: ‘mon’,‘tue’,‘wed’,‘thu’,‘fri’)
- duration: last contact duration, in seconds (numeric). Important note: this attribute highly affects the output target (e.g., if duration=0 then y=‘no’). Yet, the duration is not known before a call is performed. Also, after the end of the call y is obviously known. Thus, this input should only be included for benchmark purposes and should be discarded if the intention is to have a realistic predictive model.
other attributes 12. campaign: number of contacts performed during this campaign and for this client (numeric, includes last contact) 13. pdays: number of days that passed by after the client was last contacted from a previous campaign (numeric; 999 means client was not previously contacted) 14. previous: number of contacts performed before this campaign and for this client (numeric) 15. poutcome: outcome of the previous marketing campaign (categorical: ‘failure’,‘nonexistent’,‘success’)
social and economic context attributes 16. emp.var.rate: employment variation rate - quarterly indicator (numeric) 17. cons.price.idx: consumer price index - monthly indicator (numeric) 18. cons.conf.idx: consumer confidence index - monthly indicator (numeric) 19. euribor3m: euribor 3 month rate - daily indicator (numeric) 20. nr.employed: number of employees - quarterly indicator (numeric)
Output variable (desired target)
- y: has the client subscribed a term deposit? (binary: ‘yes’,‘no’)
Load and explore data
Let’s define a local directory local_path to keep all the files and artifacts related to this post.
Let’s make sure that the local directory folder exists.
Now download the data file to the local_path.
!wget 'https://archive.ics.uci.edu/ml/machine-learning-databases/00222/bank-additional.zip' -P {local_path}--2022-08-08 06:05:57-- https://archive.ics.uci.edu/ml/machine-learning-databases/00222/bank-additional.zip
Resolving archive.ics.uci.edu (archive.ics.uci.edu)... 128.195.10.252
Connecting to archive.ics.uci.edu (archive.ics.uci.edu)|128.195.10.252|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 444572 (434K) [application/x-httpd-php]
Saving to: ‘./datasets/2022-08-05-sagemaker-feature-store/bank-additional.zip’
bank-additional.zip 100%[===================>] 434.15K 1.55MB/s in 0.3s
2022-08-08 06:05:58 (1.55 MB/s) - ‘./datasets/2022-08-05-sagemaker-feature-store/bank-additional.zip’ saved [444572/444572]
Unzip the downloaded file.
Archive: ./datasets/2022-08-05-sagemaker-feature-store/bank-additional.zip
creating: ./datasets/2022-08-05-sagemaker-feature-store/bank-additional/
inflating: ./datasets/2022-08-05-sagemaker-feature-store/bank-additional/.DS_Store
creating: ./datasets/2022-08-05-sagemaker-feature-store/__MACOSX/
creating: ./datasets/2022-08-05-sagemaker-feature-store/__MACOSX/bank-additional/
inflating: ./datasets/2022-08-05-sagemaker-feature-store/__MACOSX/bank-additional/._.DS_Store
inflating: ./datasets/2022-08-05-sagemaker-feature-store/bank-additional/.Rhistory
inflating: ./datasets/2022-08-05-sagemaker-feature-store/bank-additional/bank-additional-full.csv
inflating: ./datasets/2022-08-05-sagemaker-feature-store/bank-additional/bank-additional-names.txt
inflating: ./datasets/2022-08-05-sagemaker-feature-store/bank-additional/bank-additional.csv
inflating: ./datasets/2022-08-05-sagemaker-feature-store/__MACOSX/._bank-additional Extracted files contains multiple datasets. We will use bank-additional-full.csv which has all the examples (41188) and 20 inputs, ordered by date.
##
# define data file path
local_data_file = f"{local_path}bank-additional/bank-additional-full.csv"
local_data_file'./datasets/2022-08-05-sagemaker-feature-store/bank-additional/bank-additional-full.csv'Let’s read the dataset and explore it.
import pandas as pd
pd.set_option("display.max_columns", 500)
pd.set_option("display.width", 1000)
df = pd.read_csv(local_data_file, sep=";")
print("df.shape: ", df.shape)
df.head()df.shape: (41188, 21)| age | job | marital | education | default | housing | loan | contact | month | day_of_week | duration | campaign | pdays | previous | poutcome | emp.var.rate | cons.price.idx | cons.conf.idx | euribor3m | nr.employed | y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 56 | housemaid | married | basic.4y | no | no | no | telephone | may | mon | 261 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no |
| 1 | 57 | services | married | high.school | unknown | no | no | telephone | may | mon | 149 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no |
| 2 | 37 | services | married | high.school | no | yes | no | telephone | may | mon | 226 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no |
| 3 | 40 | admin. | married | basic.6y | no | no | no | telephone | may | mon | 151 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no |
| 4 | 56 | services | married | high.school | no | no | yes | telephone | may | mon | 307 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no |
Creating a feature group
A feature group in the SageMaker feature store defines the metadata, feature definition, unique identifier for data entries, and other store configurations.
There are two ways to create a feature group in SageMaker. - Using SageMaker Studio IDE - SageMaker Python SDK
Considerations for creating a feature group
- Supported data types in feature group are: string, integral, and fractional
- There should be a feature that can uniquely identify each row
- There should be a feature that defines event time (event_time). This feature is required for versioning and time travel. Excepted data types for this feature are string or fractional.
- For
Stringtype event time has to be ISO-8601 format in UTC time with theyyyy-MM-dd'T'HH:mm:ssZoryyyy-MM-dd'T'HH:mm:ss.SSSZpatterns - For
Fractionaltype, the values are expected to be in seconds from Unix epoch time with millisecond precision
- For
Our dataset does not have a feature that can uniquely identify each row. So let’s create one.
Similarly, we also need to create an event time feature. For this, we will use string type with yyyy-MM-dd'T'HH:mm:ss.SSSZ pattern.
from datetime import datetime, timezone, date
def generate_event_timestamp():
# naive datetime representing local time
naive_dt = datetime.now()
# take timezone into account
aware_dt = naive_dt.astimezone()
# time in UTC
utc_dt = aware_dt.astimezone(timezone.utc)
# transform to ISO-8601 format
event_time = utc_dt.isoformat(timespec="milliseconds")
event_time = event_time.replace("+00:00", "Z")
return event_timeLet’s check our dataset with two new features.
| age | job | marital | education | default | housing | loan | contact | month | day_of_week | duration | campaign | pdays | previous | poutcome | emp.var.rate | cons.price.idx | cons.conf.idx | euribor3m | nr.employed | y | FS_id | FS_event_time | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 56 | housemaid | married | basic.4y | no | no | no | telephone | may | mon | 261 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no | 0 | 2022-08-08T06:06:07.524Z |
| 1 | 57 | services | married | high.school | unknown | no | no | telephone | may | mon | 149 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no | 1 | 2022-08-08T06:06:07.524Z |
| 2 | 37 | services | married | high.school | no | yes | no | telephone | may | mon | 226 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no | 2 | 2022-08-08T06:06:07.524Z |
| 3 | 40 | admin. | married | basic.6y | no | no | no | telephone | may | mon | 151 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no | 3 | 2022-08-08T06:06:07.524Z |
| 4 | 56 | services | married | high.school | no | no | yes | telephone | may | mon | 307 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no | 4 | 2022-08-08T06:06:07.524Z |
Initialize SageMaker session.
import sagemaker
session = sagemaker.Session()
role = sagemaker.get_execution_role()
bucket = session.default_bucket()
region = session.boto_region_name
print("sagemaker.__version__: ", sagemaker.__version__)
print("Session: ", session)
print("Role: ", role)
print("Bucket: ", bucket)
print("Region: ", region)sagemaker.__version__: 2.99.0
Session: <sagemaker.session.Session object at 0x7fb40934c890>
Role: arn:aws:iam::801598032724:role/service-role/AmazonSageMaker-ExecutionRole-20220804T174502
Bucket: sagemaker-us-east-1-801598032724
Region: us-east-1Feature store requires an S3 location for storing the ingested data. Let’s define it as well.
Create feature group from SageMaker studio IDE
Let’s see how we can create a feature group using SageMaker Studio IDE. You don’t need to write any code while creating a feature group using Studio IDE. From the left sidebar, use the SageMaker Resources menu to open the Feature Group pane, and click the create feature group option. This will open a new tab in IDE to create a feature group.
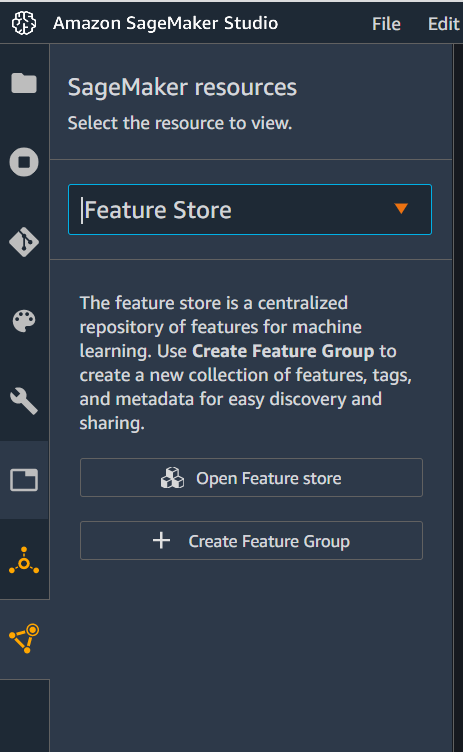
On the create feature group tab, define the following settings: - Feature group name : “bank-marketing-studio” - Description (optional) : “The data is related to direct marketing campaigns (phone calls) of a Portuguese banking institution.” - Feature group storage configurations - Enable online store : Check this box. Note that for the online store there is no S3 bucket requirement. - Enable offline store : Check this box too. - Enter S3 location from fs_offline_bucket_studio - IAM Role ARN : Default SageMaker role. - Enable Data Catalog for offline store - Select continue
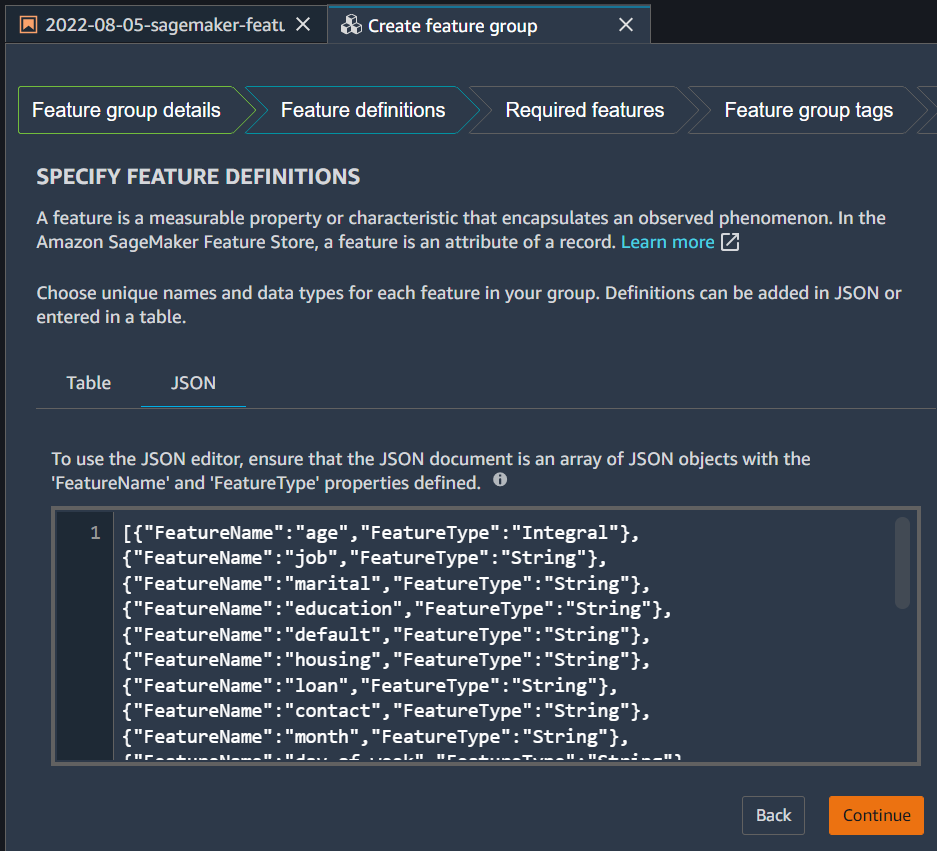
On the next page, you will be asked to specify feature definitions. There are two ways to define them. - Using Table, and manually fill each feature and its type - Using JSON. We will use this option to define the features and their types.
Remember that the feature group only supports three data types: string, integral, and fractional. So we need to create a mapping between Pandas Dataframe data types and that of a feature store. - “object” -> “String” - “int64” -> “Integral” - “float64” -> “Fractional”
age int64
job object
marital object
education object
default object
housing object
loan object
contact object
month object
day_of_week object
duration int64
campaign int64
pdays int64
previous int64
poutcome object
emp.var.rate float64
cons.price.idx float64
cons.conf.idx float64
euribor3m float64
nr.employed float64
y object
FS_id int64
FS_event_time object
dtype: objectFeature names allow alphanumeric characters including dashes and underscores. So let’s remove the “.” character from the feature names.
['age',
'job',
'marital',
'education',
'default',
'housing',
'loan',
'contact',
'month',
'day_of_week',
'duration',
'campaign',
'pdays',
'previous',
'poutcome',
'emp_var_rate',
'cons_price_idx',
'cons_conf_idx',
'euribor3m',
'nr_employed',
'y',
'FS_id',
'FS_event_time']Now we are ready to prepare JSON for feature definitions. JSON created should be of the following format.
[
{
"FeatureName": "age",
"FeatureType": "Integral"
}
]Let’s prepare it.
df_features = pd.DataFrame({"FeatureName": feature_names, "FeatureType": feature_types})
print(df_features.to_json(orient="records"))[{"FeatureName":"age","FeatureType":"Integral"},{"FeatureName":"job","FeatureType":"String"},{"FeatureName":"marital","FeatureType":"String"},{"FeatureName":"education","FeatureType":"String"},{"FeatureName":"default","FeatureType":"String"},{"FeatureName":"housing","FeatureType":"String"},{"FeatureName":"loan","FeatureType":"String"},{"FeatureName":"contact","FeatureType":"String"},{"FeatureName":"month","FeatureType":"String"},{"FeatureName":"day_of_week","FeatureType":"String"},{"FeatureName":"duration","FeatureType":"Integral"},{"FeatureName":"campaign","FeatureType":"Integral"},{"FeatureName":"pdays","FeatureType":"Integral"},{"FeatureName":"previous","FeatureType":"Integral"},{"FeatureName":"poutcome","FeatureType":"String"},{"FeatureName":"emp_var_rate","FeatureType":"Fractional"},{"FeatureName":"cons_price_idx","FeatureType":"Fractional"},{"FeatureName":"cons_conf_idx","FeatureType":"Fractional"},{"FeatureName":"euribor3m","FeatureType":"Fractional"},{"FeatureName":"nr_employed","FeatureType":"Fractional"},{"FeatureName":"y","FeatureType":"String"},{"FeatureName":"FS_id","FeatureType":"Integral"},{"FeatureName":"FS_event_time","FeatureType":"String"}]Copy the JSON from the last cell output and past it in feature definition JSON input. Click continue
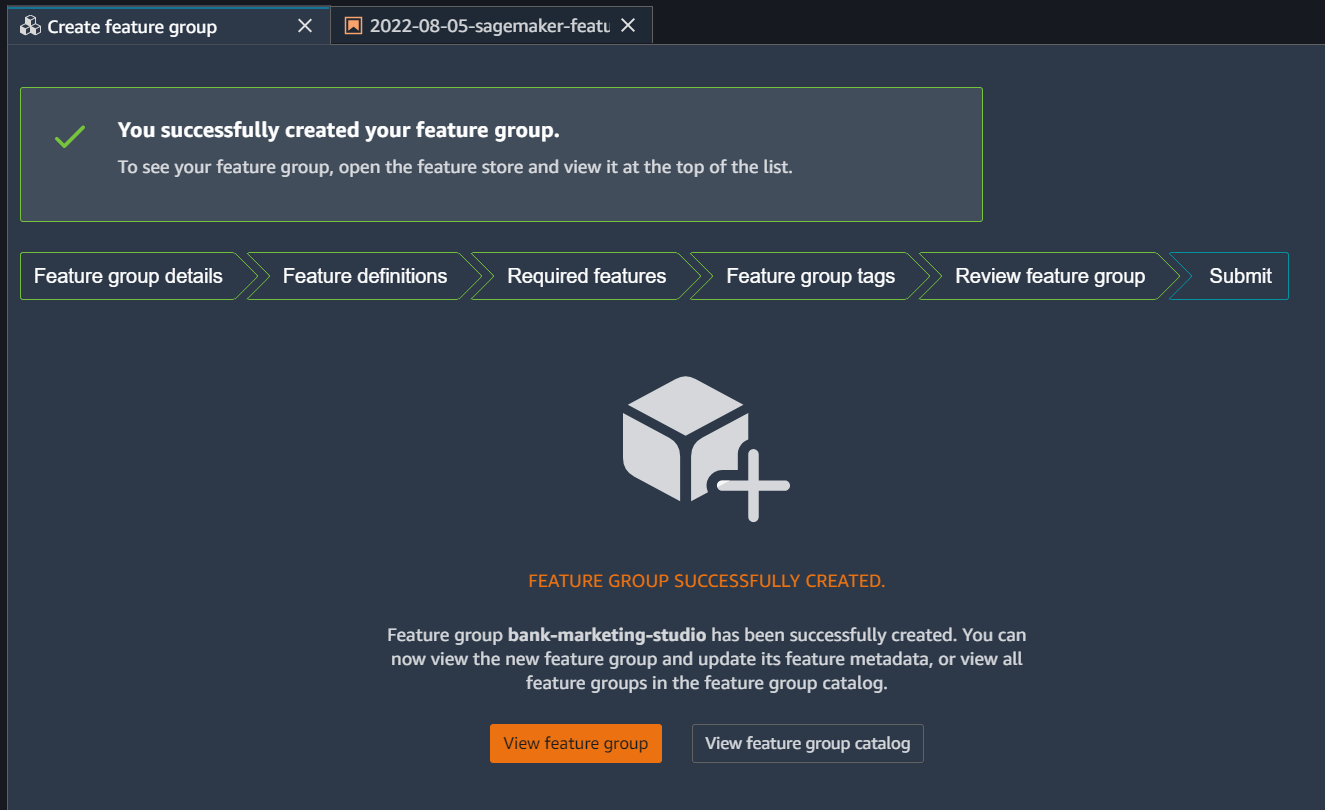
On the next page, it will ask for the required features. - record identifier feature name : select FS_ID - event type feature name : select FS_event_time
Click continue and create the feature group.
Create feature group from SageMaker SDK
We have seen how we can create a feature group from SageMaker studio IDE. Let’s also see how to create it using SageMaker SDK.
I have created a FeatureGroup, now we need to define its schema (FeatureDefinitions). When I check the SageMaker Python SDK Feature Store APIs reference, I could not find any method to provide FeatureDefinitions to a feature group. But feature store documentation examples amazon_sagemaker_featurestore mention that we can use feature_group.load_feature_definitions() method to load the feature definitions from Pandas dataframe. When I checked the sagemaker-python-sdk GitHub page there is an open issue that says “The documentation does not include the load_feature_definitions() method for the FeatureGroup class”, and is still open.
To get more understanding of this method we can check the source code for sagemaker feature group class github.com/aws/sagemaker-python-sdk/blob/master/src/sagemaker/feature_store/feature_group.py. If we check the signature and documentation for this method it says:
def load_feature_definitions(
self,
data_frame: DataFrame,
) -> Sequence[FeatureDefinition]:
"""Load feature definitions from a Pandas DataFrame.
Column name is used as feature name. Feature type is inferred from the dtype
of the column. Dtype int_, int8, int16, int32, int64, uint8, uint16, uint32
and uint64 are mapped to Integral feature type. Dtype float_, float16, float32
and float64 are mapped to Fractional feature type. string dtype is mapped to
String feature type.
No feature definitions will be loaded if the given data_frame contains
unsupported dtypes.
Args:
data_frame (DataFrame):
Returns:
list of FeatureDefinition
"""That is * It loads feature definitions from a Pandas DataFrame * DataFrame column names are used as feature names * Feature types are inferred from the dtype of columns * Dtype int_, int8, int16, int32, int64, uint8, uint16, uint32 and uint64 are mapped to Integral feature type * Dtype float_, float16, float32 and float64 are mapped to Fractional feature type * Dtype string is mapped to String feature type * No feature definitions will be loaded if the given data_frame contains unsupported dtypes
In the last section, we have seen that our dataframe has object data types that are not supported. For backward compatibility reasons, Pandas DataFrame infers columns with strings as object data type. With Pandas 1.0 onwards we can explicitly use string type for such columns.
Let’s see what happens when we use unsupported data types for feature definition.
##
# load unsupported feature definitions. This will generate an error.
feature_group.load_feature_definitions(data_frame=df)--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-24-f77a8abe3ce7> in <module> 1 ## 2 # load unsupported feature definitions. This will generate an error. ----> 3 feature_group.load_feature_definitions(data_frame=df) /opt/conda/lib/python3.7/site-packages/sagemaker/feature_store/feature_group.py in load_feature_definitions(self, data_frame) 570 else: 571 raise ValueError( --> 572 f"Failed to infer Feature type based on dtype {data_frame[column].dtype} " 573 f"for column {column}." 574 ) ValueError: Failed to infer Feature type based on dtype object for column job.
It throws an error, “ValueError: Failed to infer Feature type based on dtype object for column job.”
Okay, let’s convet columns to proper data types.
['job',
'marital',
'education',
'default',
'housing',
'loan',
'contact',
'month',
'day_of_week',
'poutcome',
'y',
'FS_event_time']Let’s verify the data types of all columns.
age int64
job string
marital string
education string
default string
housing string
loan string
contact string
month string
day_of_week string
duration int64
campaign int64
pdays int64
previous int64
poutcome string
emp.var.rate float64
cons.price.idx float64
cons.conf.idx float64
euribor3m float64
nr.employed float64
y string
FS_id int64
FS_event_time string
dtype: object| age | job | marital | education | default | housing | loan | contact | month | day_of_week | duration | campaign | pdays | previous | poutcome | emp.var.rate | cons.price.idx | cons.conf.idx | euribor3m | nr.employed | y | FS_id | FS_event_time | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 56 | housemaid | married | basic.4y | no | no | no | telephone | may | mon | 261 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no | 0 | 2022-08-08T06:06:07.524Z |
| 1 | 57 | services | married | high.school | unknown | no | no | telephone | may | mon | 149 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no | 1 | 2022-08-08T06:06:07.524Z |
| 2 | 37 | services | married | high.school | no | yes | no | telephone | may | mon | 226 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no | 2 | 2022-08-08T06:06:07.524Z |
| 3 | 40 | admin. | married | basic.6y | no | no | no | telephone | may | mon | 151 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no | 3 | 2022-08-08T06:06:07.524Z |
| 4 | 56 | services | married | high.school | no | no | yes | telephone | may | mon | 307 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no | 4 | 2022-08-08T06:06:07.524Z |
Let’s load the feature definitions again.
[FeatureDefinition(feature_name='age', feature_type=<FeatureTypeEnum.INTEGRAL: 'Integral'>),
FeatureDefinition(feature_name='job', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='marital', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='education', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='default', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='housing', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='loan', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='contact', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='month', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='day_of_week', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='duration', feature_type=<FeatureTypeEnum.INTEGRAL: 'Integral'>),
FeatureDefinition(feature_name='campaign', feature_type=<FeatureTypeEnum.INTEGRAL: 'Integral'>),
FeatureDefinition(feature_name='pdays', feature_type=<FeatureTypeEnum.INTEGRAL: 'Integral'>),
FeatureDefinition(feature_name='previous', feature_type=<FeatureTypeEnum.INTEGRAL: 'Integral'>),
FeatureDefinition(feature_name='poutcome', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='emp.var.rate', feature_type=<FeatureTypeEnum.FRACTIONAL: 'Fractional'>),
FeatureDefinition(feature_name='cons.price.idx', feature_type=<FeatureTypeEnum.FRACTIONAL: 'Fractional'>),
FeatureDefinition(feature_name='cons.conf.idx', feature_type=<FeatureTypeEnum.FRACTIONAL: 'Fractional'>),
FeatureDefinition(feature_name='euribor3m', feature_type=<FeatureTypeEnum.FRACTIONAL: 'Fractional'>),
FeatureDefinition(feature_name='nr.employed', feature_type=<FeatureTypeEnum.FRACTIONAL: 'Fractional'>),
FeatureDefinition(feature_name='y', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='FS_id', feature_type=<FeatureTypeEnum.INTEGRAL: 'Integral'>),
FeatureDefinition(feature_name='FS_event_time', feature_type=<FeatureTypeEnum.STRING: 'String'>)]We have defined our feature group and its feature definitions, but it has not been created. To create it we need to call create method on the feature group. For this let’s define s3 URI for our feature store offline data storage.
's3://sagemaker-us-east-1-801598032724/2022-08-05-sagemaker-feature-store/fs_offline/sdk'##
# Now create feature group
record_identifier_name = "FS_id"
event_time_feature_name = "FS_event_time"
description = "The data is related with direct marketing campaigns (phone calls) of a Portuguese banking institution"
feature_group.create(
record_identifier_name=record_identifier_name,
event_time_feature_name=event_time_feature_name,
enable_online_store=True,
s3_uri=fs_offline_bucket_sdk,
role_arn=role,
description=description,
)--------------------------------------------------------------------------- ClientError Traceback (most recent call last) <ipython-input-31-5459ca8fa447> in <module> 11 s3_uri=fs_offline_bucket_sdk, 12 role_arn=role, ---> 13 description=description, 14 ) /opt/conda/lib/python3.7/site-packages/sagemaker/feature_store/feature_group.py in create(self, s3_uri, record_identifier_name, event_time_feature_name, role_arn, online_store_kms_key_id, enable_online_store, offline_store_kms_key_id, disable_glue_table_creation, data_catalog_config, description, tags) 519 ) 520 --> 521 return self.sagemaker_session.create_feature_group(**create_feature_store_args) 522 523 def delete(self): /opt/conda/lib/python3.7/site-packages/sagemaker/session.py in create_feature_group(self, feature_group_name, record_identifier_name, event_time_feature_name, feature_definitions, role_arn, online_store_config, offline_store_config, description, tags) 4076 Tags=tags, 4077 ) -> 4078 return self.sagemaker_client.create_feature_group(**kwargs) 4079 4080 def describe_feature_group( /opt/conda/lib/python3.7/site-packages/botocore/client.py in _api_call(self, *args, **kwargs) 506 ) 507 # The "self" in this scope is referring to the BaseClient. --> 508 return self._make_api_call(operation_name, kwargs) 509 510 _api_call.__name__ = str(py_operation_name) /opt/conda/lib/python3.7/site-packages/botocore/client.py in _make_api_call(self, operation_name, api_params) 913 error_code = parsed_response.get("Error", {}).get("Code") 914 error_class = self.exceptions.from_code(error_code) --> 915 raise error_class(parsed_response, operation_name) 916 else: 917 return parsed_response ClientError: An error occurred (ValidationException) when calling the CreateFeatureGroup operation: 4 validation errors detected: Value 'emp.var.rate' at 'featureDefinitions.16.member.featureName' failed to satisfy constraint: Member must satisfy regular expression pattern: ^[a-zA-Z0-9]([-_]*[a-zA-Z0-9]){0,63}; Value 'cons.price.idx' at 'featureDefinitions.17.member.featureName' failed to satisfy constraint: Member must satisfy regular expression pattern: ^[a-zA-Z0-9]([-_]*[a-zA-Z0-9]){0,63}; Value 'cons.conf.idx' at 'featureDefinitions.18.member.featureName' failed to satisfy constraint: Member must satisfy regular expression pattern: ^[a-zA-Z0-9]([-_]*[a-zA-Z0-9]){0,63}; Value 'nr.employed' at 'featureDefinitions.20.member.featureName' failed to satisfy constraint: Member must satisfy regular expression pattern: ^[a-zA-Z0-9]([-_]*[a-zA-Z0-9]){0,63}
We got an error as we have not fixed feature names. Error is saying that the feature name should satisfy the regular expression pattern: ^[a-zA-Z0-9]([-_]*[a-zA-Z0-9]){0,63}. Let’s fix our column names.
col_names = df.columns.tolist()
for idx in range(len(col_names)):
col_names[idx] = col_names[idx].replace(".", "_")
df.columns = col_names
df.head()| age | job | marital | education | default | housing | loan | contact | month | day_of_week | duration | campaign | pdays | previous | poutcome | emp_var_rate | cons_price_idx | cons_conf_idx | euribor3m | nr_employed | y | FS_id | FS_event_time | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 56 | housemaid | married | basic.4y | no | no | no | telephone | may | mon | 261 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no | 0 | 2022-08-08T06:06:07.524Z |
| 1 | 57 | services | married | high.school | unknown | no | no | telephone | may | mon | 149 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no | 1 | 2022-08-08T06:06:07.524Z |
| 2 | 37 | services | married | high.school | no | yes | no | telephone | may | mon | 226 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no | 2 | 2022-08-08T06:06:07.524Z |
| 3 | 40 | admin. | married | basic.6y | no | no | no | telephone | may | mon | 151 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no | 3 | 2022-08-08T06:06:07.524Z |
| 4 | 56 | services | married | high.school | no | no | yes | telephone | may | mon | 307 | 1 | 999 | 0 | nonexistent | 1.1 | 93.994 | -36.4 | 4.857 | 5191.0 | no | 4 | 2022-08-08T06:06:07.524Z |
After updating feature names, load the feature group definitions again.
[FeatureDefinition(feature_name='age', feature_type=<FeatureTypeEnum.INTEGRAL: 'Integral'>),
FeatureDefinition(feature_name='job', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='marital', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='education', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='default', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='housing', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='loan', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='contact', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='month', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='day_of_week', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='duration', feature_type=<FeatureTypeEnum.INTEGRAL: 'Integral'>),
FeatureDefinition(feature_name='campaign', feature_type=<FeatureTypeEnum.INTEGRAL: 'Integral'>),
FeatureDefinition(feature_name='pdays', feature_type=<FeatureTypeEnum.INTEGRAL: 'Integral'>),
FeatureDefinition(feature_name='previous', feature_type=<FeatureTypeEnum.INTEGRAL: 'Integral'>),
FeatureDefinition(feature_name='poutcome', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='emp_var_rate', feature_type=<FeatureTypeEnum.FRACTIONAL: 'Fractional'>),
FeatureDefinition(feature_name='cons_price_idx', feature_type=<FeatureTypeEnum.FRACTIONAL: 'Fractional'>),
FeatureDefinition(feature_name='cons_conf_idx', feature_type=<FeatureTypeEnum.FRACTIONAL: 'Fractional'>),
FeatureDefinition(feature_name='euribor3m', feature_type=<FeatureTypeEnum.FRACTIONAL: 'Fractional'>),
FeatureDefinition(feature_name='nr_employed', feature_type=<FeatureTypeEnum.FRACTIONAL: 'Fractional'>),
FeatureDefinition(feature_name='y', feature_type=<FeatureTypeEnum.STRING: 'String'>),
FeatureDefinition(feature_name='FS_id', feature_type=<FeatureTypeEnum.INTEGRAL: 'Integral'>),
FeatureDefinition(feature_name='FS_event_time', feature_type=<FeatureTypeEnum.STRING: 'String'>)]Now create the feature group.
##
# create feature group
feature_group.create(
record_identifier_name=record_identifier_name,
event_time_feature_name=event_time_feature_name,
enable_online_store=True,
s3_uri=fs_offline_bucket_sdk,
role_arn=role,
description=description,
){'FeatureGroupArn': 'arn:aws:sagemaker:us-east-1:801598032724:feature-group/bank-marketing-sdk',
'ResponseMetadata': {'RequestId': '5c2afeb1-fa03-442b-a3ee-80b1b0ae1069',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amzn-requestid': '5c2afeb1-fa03-442b-a3ee-80b1b0ae1069',
'content-type': 'application/x-amz-json-1.1',
'content-length': '95',
'date': 'Mon, 08 Aug 2022 06:06:32 GMT'},
'RetryAttempts': 0}}Feature group creation is an async method, and you need to wait for its creation before ingesting any data into it. For this you can use feature_group.describe method to get feature store creation status.
We can create a wrapper function around this method to wait till the feature group is ready.
import time
def wait_for_feature_group_creation_complete(feature_group):
status = feature_group.describe().get("FeatureGroupStatus")
print(f"Initial status: {status}")
while status == "Creating":
print(f"Waiting for feature group: {feature_group.name} to be created ...")
time.sleep(5)
status = feature_group.describe().get("FeatureGroupStatus")
print(f"FeatureGroup {feature_group.name} was successfully created.")
wait_for_feature_group_creation_complete(feature_group)Initial status: Creating
Waiting for feature group: bank-marketing-sdk to be created ...
Waiting for feature group: bank-marketing-sdk to be created ...
Waiting for feature group: bank-marketing-sdk to be created ...
Waiting for feature group: bank-marketing-sdk to be created ...
FeatureGroup bank-marketing-sdk was successfully created.Ingest data to feature group
Let’s ingest our data frame into this feature group.
IngestionManagerPandas(feature_group_name='bank-marketing-sdk', sagemaker_fs_runtime_client_config=<botocore.config.Config object at 0x7fb406ab9450>, max_workers=5, max_processes=1, profile_name=None, _async_result=<multiprocess.pool.MapResult object at 0x7fb405669810>, _processing_pool=<pool ProcessPool(ncpus=1)>, _failed_indices=[])We can control the ingestion run time with max_processes and max_workers arguments. * max_processes defines the number of processes that will be created to ingest different partitions of the DataFrame in parallel * max_workers defines the number threads for each processor
For large datasets, instead of using ingestion API we can place the data directly on feature group S3 bucket offline storage location. For a detailed discussion on this topic follow the post from Heiko Hotz: ingesting-historical-feature-data-into-sagemaker-feature-store
Accessing features from feature store
Now that we have our data available in the feature repository, we can access it from online and offline feature stores.
Accessing online feature store from SDK
Boto3 SDK sagemaker-featurestore-runtime allows us to interact with the online feature store. These are the available methods:
- batch_get_record()
- can_paginate()
- close()
- delete_record()
- get_paginator()
- get_record()
- get_waiter()
- put_record()
To read more about them use Boto3 SageMakerFeatureStoreRuntime documentation.
##
# select any random id to query online store
sample_feature_id = str(df.sample().index.values[0])
sample_feature_id'37156'Now query the online store.
%%timeit
featurestore_runtime_client.get_record(FeatureGroupName=feature_group_name,
RecordIdentifierValueAsString=sample_feature_id)8.37 ms ± 238 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)feature_record = featurestore_runtime_client.get_record(
FeatureGroupName=feature_group_name, RecordIdentifierValueAsString=sample_feature_id
)
feature_record{'ResponseMetadata': {'RequestId': '946376b7-7745-4b25-9885-e93ba7a284a5',
'HTTPStatusCode': 200,
'HTTPHeaders': {'x-amzn-requestid': '946376b7-7745-4b25-9885-e93ba7a284a5',
'content-type': 'application/json',
'content-length': '1189',
'date': 'Mon, 08 Aug 2022 06:08:49 GMT'},
'RetryAttempts': 0},
'Record': [{'FeatureName': 'age', 'ValueAsString': '39'},
{'FeatureName': 'job', 'ValueAsString': 'blue-collar'},
{'FeatureName': 'marital', 'ValueAsString': 'married'},
{'FeatureName': 'education', 'ValueAsString': 'basic.9y'},
{'FeatureName': 'default', 'ValueAsString': 'no'},
{'FeatureName': 'housing', 'ValueAsString': 'no'},
{'FeatureName': 'loan', 'ValueAsString': 'no'},
{'FeatureName': 'contact', 'ValueAsString': 'cellular'},
{'FeatureName': 'month', 'ValueAsString': 'aug'},
{'FeatureName': 'day_of_week', 'ValueAsString': 'wed'},
{'FeatureName': 'duration', 'ValueAsString': '394'},
{'FeatureName': 'campaign', 'ValueAsString': '1'},
{'FeatureName': 'pdays', 'ValueAsString': '999'},
{'FeatureName': 'previous', 'ValueAsString': '0'},
{'FeatureName': 'poutcome', 'ValueAsString': 'nonexistent'},
{'FeatureName': 'emp_var_rate', 'ValueAsString': '-2.9'},
{'FeatureName': 'cons_price_idx', 'ValueAsString': '92.201'},
{'FeatureName': 'cons_conf_idx', 'ValueAsString': '-31.4'},
{'FeatureName': 'euribor3m', 'ValueAsString': '0.884'},
{'FeatureName': 'nr_employed', 'ValueAsString': '5076.2'},
{'FeatureName': 'y', 'ValueAsString': 'yes'},
{'FeatureName': 'FS_id', 'ValueAsString': '37156'},
{'FeatureName': 'FS_event_time',
'ValueAsString': '2022-08-08T06:06:07.834Z'}]}Accessing offline feature store from SDK
Let’s query the offline store to get the same data. For offline feature storage, SageMaker stages the data in S3 bucket and creates AWS Data Catalog on it. This catalog is registered in AWS Athena and we can use Athena APIs to query offline store.
AthenaQuery(catalog='AwsDataCatalog', database='sagemaker_featurestore', table_name='bank-marketing-sdk-1659938792', sagemaker_session=<sagemaker.session.Session object at 0x7fb40934c890>, _current_query_execution_id=None, _result_bucket=None, _result_file_prefix=None)'SELECT * FROM "bank-marketing-sdk-1659938792" WHERE FS_id = 37156'%%timeit
query.run(query_string=query_string,output_location=f's3://{bucket}/{bucket_prefix}/query_results/')
query.wait()5.21 s ± 29.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)Notice that the offline store has taken a much longer time to return the results compared to the online store.
| age | job | marital | education | default | housing | loan | contact | month | day_of_week | duration | campaign | pdays | previous | poutcome | emp_var_rate | cons_price_idx | cons_conf_idx | euribor3m | nr_employed | y | fs_id | fs_event_time | write_time | api_invocation_time | is_deleted |
|---|
Data in an online store becomes available immediately but it can take a few minutes to become available in an offline store. That is why we have not received any data in the last cell. Let’s run the same query again after a few minutes.
##
# run query again
query.run(query_string=query_string,output_location=f's3://{bucket}/{bucket_prefix}/query_results/')
query.wait()
# get query response
dataset = query.as_dataframe()
dataset.head()| age | job | marital | education | default | housing | loan | contact | month | day_of_week | duration | campaign | pdays | previous | poutcome | emp_var_rate | cons_price_idx | cons_conf_idx | euribor3m | nr_employed | y | fs_id | fs_event_time | write_time | api_invocation_time | is_deleted | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 39 | blue-collar | married | basic.9y | no | no | no | cellular | aug | wed | 394 | 1 | 999 | 0 | nonexistent | -2.9 | 92.201 | -31.4 | 0.884 | 5076.2 | yes | 37156 | 2022-08-08T06:06:07.834Z | 2022-08-08 06:13:03.665 | 2022-08-08 06:07:43.000 | False |
Accessing offline store from Athena
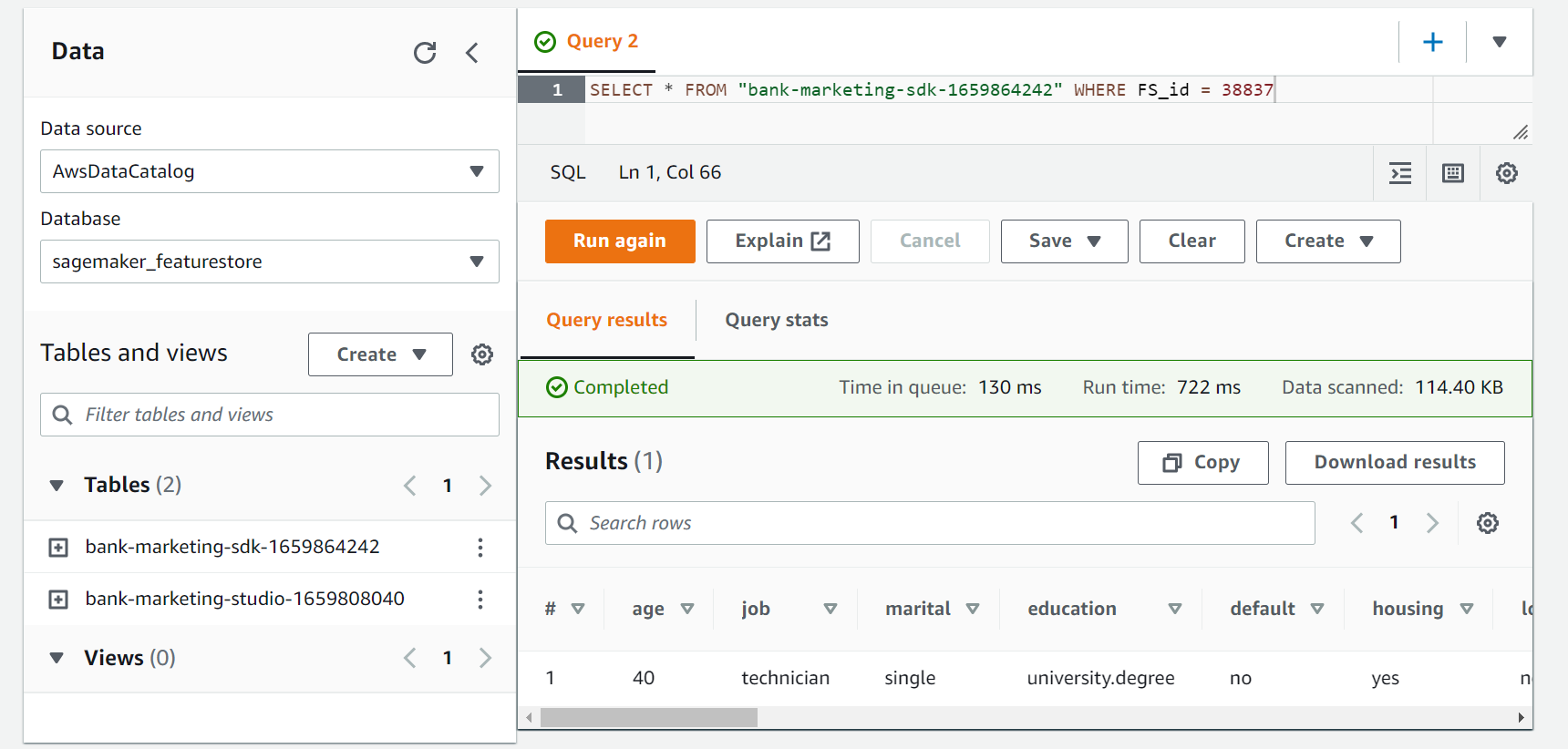
This time lets query the offline feature store directly from AWS Athena service.
Clean up
Run the last cell to delete the feature store if no longer needed.