import json
import boto3
import os
DataSync_task_arn = 'arn:aws:datasync:us-east-1:801598032724:task/task-0c04a4a15668b6b8a'
DataSync = boto3.client('datasync')
def lambda_handler(event, context):
objectKey = ''
try:
objectKey = event["Records"][0]["s3"]["object"]["key"]
except KeyError:
raise KeyError("Received invalid event - unable to locate Object key to upload.", event)
response = DataSync.start_task_execution(
TaskArn=DataSync_task_arn,
OverrideOptions={
'OverwriteMode' : 'ALWAYS',
'PreserveDeletedFiles' : 'REMOVE',
},
Includes=[
{
'FilterType': 'SIMPLE_PATTERN',
'Value': '/' + os.path.basename(objectKey)
}
]
)
print(f"response= {response}")
return {
'response' : response
} AWS EFS Sync to S3 Using DataSync
aws
lambda
efs
s3
synchonization
datasync
A tutorial to synchronize EFS with S3 bucket using DataSync service.
Keywords
aws, lambda, s3, efs, sync, python, datasync

About
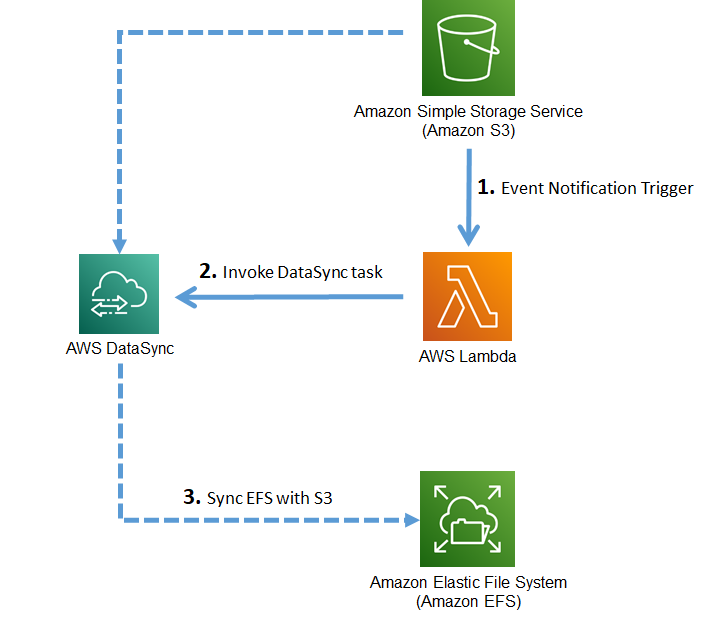
This post is to document all the steps required to synchronize AWS EFS with an S3 bucket using DataSync service. The flow of information is from S3 to EFS and not vice versa.
We will discuss two approaches to trigger the datasync service * Trigger-based. Whenever there is a new file uploaded in S3 bucket * Schedule-based. A trigger will run datasync at scheduled intervals
Once a datasync service is invoked it will take care of syncing files from S3 bucket to EFS.
Environment Details
- Python = 3.9.x
Steps for trigger based approach
Create an S3 bucket
Let’s first create an S3 bucket that will contain our data, and this is the bucket we would like to be in sync with EFS. I am naming the bucket as mydata-202203. You may name it as you please. Choose a region of your choice and leave the rest of the settings as defaults.
Create an EFS
From EFS console give name as mydata-efs. I am using default VPC for this post. Use Regional availability settings. Click Create. Once file system is created, click on Access points and create an access point for this efs to be mounted in other service. For access point use following settings * name = mydata-ap * root dir path = / * POSIX User * POSIX UID = 1000 * Group ID = 1000 * Root directory creation permissions * Owner user id = 1000 * Owner group id = 1000 * POSIX permissions = 777
Click Create.
Note on EFS security group settings
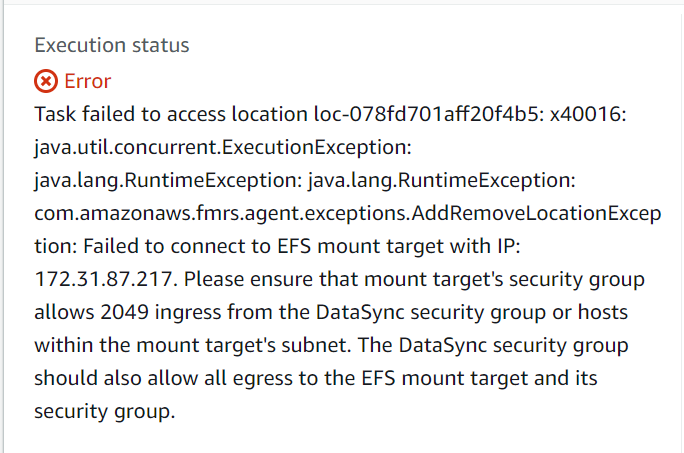
In the last section, I have used a default VPC security group (sg) while creating EFS. Default sg allows traffic for all protocols and all ports, both inbound and outbound. But if you are using a custom security group then make sure that you have an inbound rule for * Type = NFS * Protocol = TCP * Port range = 2049
Otherwise, you will not be able to access EFS using NFS clients, and if you find an error similar to the below then it means you need to check the security group settings.
Create DataSync service task
- configure source location = create a new location
- location type = Amazon S3
- region = us-east-1
- s3 bucket = mydata-202203
- s3 storage class = standard
- folder = [leave empty]
- IAM role = click on auto generate
- configure destination location = create a new location
- location type = EFS
- region = us-east-1
- efs file system = mydata-efs
- mount path = /efs
- subnet = us-east-1a
- security group = default
- configure settings
- task name = mydata-datasync
- task execution configuration
- verify data = verify only the data transferred
- set bandwidth limit = use available
- data transfer configuration
- data to scan = entire source location
- transfer mode = transfer only the data that has changed
- uncheck “keep deleted files”
- check “overwrite files”
- schedule
- frequency = not scheduled
- task logging
- cloudwatch log group = autogenerate
Click “next”. Review and Launch.
Test DataSync Service
Let’s test datasync service by manually starting it. If S3 bucket is empty then datasync will throw an exception as below
![]()
This is not an issue. Just place some files (test1.txt in my case) in the bucket and start the datasync service again. If it executes successfully then you will get a message as Execution Status = Success
DataSync can work without Internet Gateway or VPC Endpoint
One thing I noticed is that DataSync service can work even without the presence of an internet gateway or S3 service endpoint. EFS is VPC bound and S3 is global but DataSync can still communicate with both of them. This was different for Lambda. Once Lambda is configured for a VPC then it is not able to access S3 without an internet gateway or VPC endpoint.
Verify EFS by mounting it to the EC2 machine
In the last section, we ran DataSync and it successfully copied files from S3 to EFS. So let’s verify our files from EFS by mounting it to an EC2 instance.
Create an EC2 machine * AMI = Amazon Linux 2 AMI (HVM) - Kernel 5.10, SSD Volume Type * Intance type = t2.micro (free tier) * Instance details * Network = default VPC * Auto-assign Public IP = Enable * Review and Lanunch > Launch > Proceed without key pair.
Once the instance is up and running, click on it and connect using EC2 instance connect option. Create a dir ‘efs’ using the command
mkdir efsIn a separate tab open EFS, and click on the file system we have created. Click Attach. From “Mount via DNS” copy command for NFS client. paste that in EC2 bash terminal
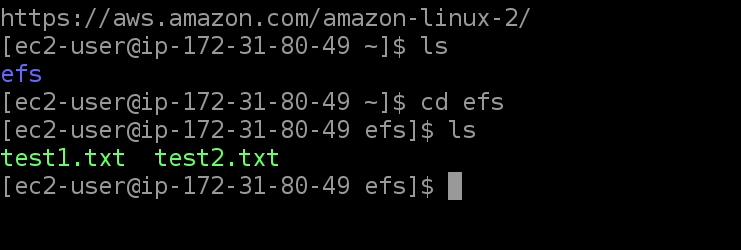
sudo mount -t nfs4 -o nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport fs-01acd308743098251.efs.us-east-1.amazonaws.com:/ efsOnce successfully mounted, verify that the file ‘test1.txt’ exists in EFS.

Create Lambda function to trigger DataSync task
Now let’s create a lambda function that will trigger the datasync task. This function will itself be triggered by an S3 event notification whenever a file is uploaded or deleted.
- Create a lambda function as
- name = datasync-trigger-s3
- runtime = Python 3.9
Leave the rest of the settings as default, update the code as below, and deploy.
In the code, we are first filtering the object key for which the event is generated. Then we trigger the datasync task and pass the object key as a filter string. With the filter key provided datasync job will only sync provided object from S3 to EFS.
Add policy AWSDataSyncFullAccess to this lambda function role otherwise it will not be able to trigger datasync task.
Configure S3 bucket event notifications
Our lambda function is ready. Now we can enable S3 bucket event notifications as put the lambda function as a target. For this from S3 bucket Properties > Event notifications > Create event notifications
- event name = object-put-delete
- event type = s3:ObjectCreated:Put, and s3:ObjectRemoved:Delete
- destination = lambda function (datasync-trigger-s3)
Click Save changes
Test DataSync task through S3 events trigger
Now let’s test our trigger by placing a new file in S3 bucket. In my case it is ‘test2.txt’. Once file is successfully uploaded we can check the EC2 instance to verify the file presence.
We can also verify that the datasync job was triggered from lambda CloudWatch logs.
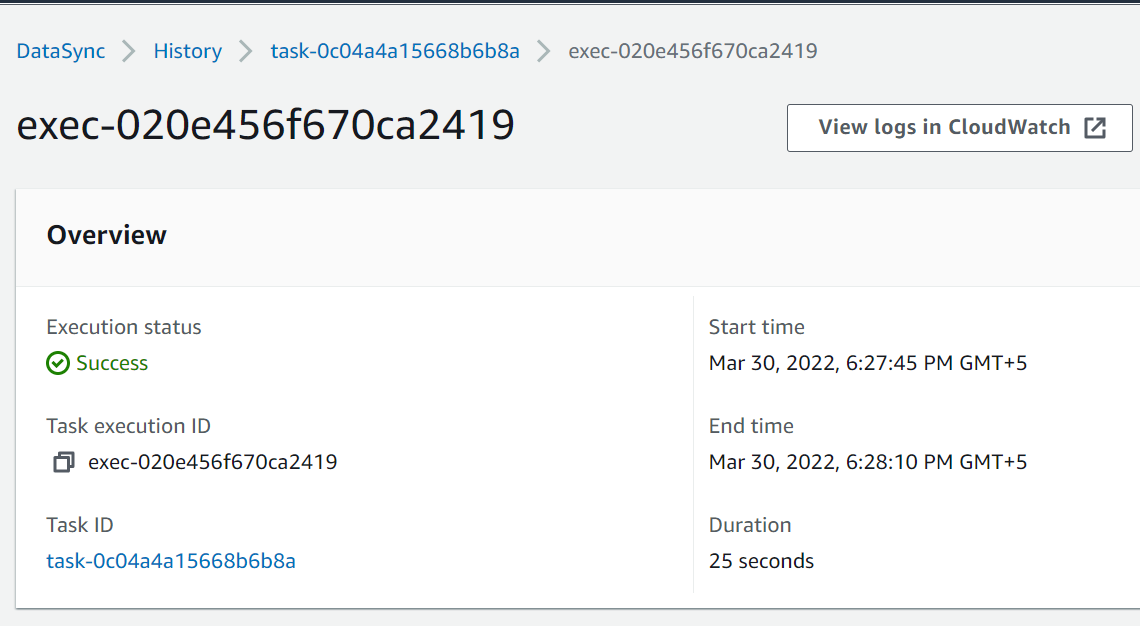
response= {'TaskExecutionArn': 'arn:aws:datasync:us-east-1:801598032724:task/task-0c04a4a15668b6b8a/execution/exec-020e456f670ca2419', 'ResponseMetadata': {'RequestId': 'c8166ce4-ef14-415c-beff-09cc7720f4a3', 'HTTPStatusCode': 200, 'HTTPHeaders': {'date': 'Wed, 30 Mar 2022 13:27:45 GMT', 'content-type': 'application/x-amz-json-1.1', 'content-length': '123', 'connection': 'keep-alive', 'x-amzn-requestid': 'c8166ce4-ef14-415c-beff-09cc7720f4a3'}, 'RetryAttempts': 0}}In the logs we have task execution id exec-020e456f670ca2419 , and we can use that to verify task’s status from datasync console.
Steps for scheduled based approach
We have seen in the last section that we can use S3 event notifications to trigger datasync tasks. Now we will discuss a schedule-based trigger for datasync task. This can be done in two ways * While creating a datasync task we can define a frequency for it to follow. But the limitation on this is that it can not be lower than a 1 hour window. * If we want to schedule a datasync task on a smaller than 1 hour window then we can use AWS EventBridge (previously CloudWatch Events) to trigger a lambda function that can inturn invoke a datasync task. In the coming section, we will follow this approach.
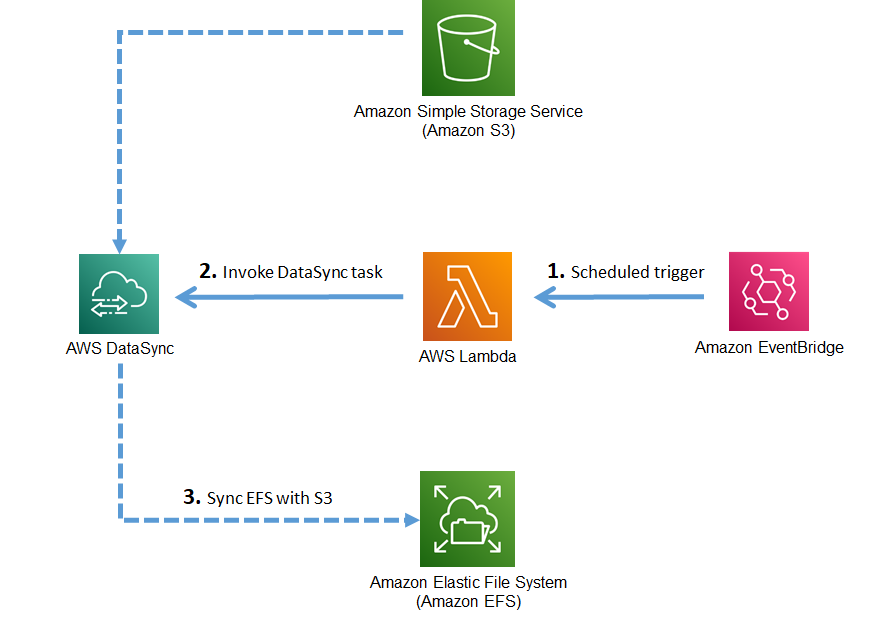
Create a lambda function
Let’s create a new lambda function with the following code. This lambda will invoke the datasync task. Add permissions to this lambda AWSDataSyncFullAccess
- function name = datasync-trigger-scheduled
- runtime = Python 3.9
import json
import boto3
import os
DataSync_task_arn = 'arn:aws:datasync:us-east-1:801598032724:task/task-0c04a4a15668b6b8a'
DataSync = boto3.client('datasync')
def lambda_handler(event, context):
response = DataSync.start_task_execution(
TaskArn=DataSync_task_arn,
OverrideOptions={
'OverwriteMode' : 'ALWAYS',
'PreserveDeletedFiles' : 'REMOVE',
}
)
print(f"response= {response}")
return {
'response' : response
} Create EventBridge event
Go to EventBridge Events > Rules > select Create Rule - Define rule details - name = datasync-trigger - event bus = default - rule type = scheduled - Define schedule - Sample event = {} - Schedule Pattern - Rate expression = 5 min - Select Targets - target = Lambda function - function = datasync-trigger-scheduled
Click Next and Create Rule
EventBridge will automatically add a policy statement to lambda function (datasync-trigger-scheduled) allowing it to trigger lambda. You can verify the policy from lambda Configurations > Permissions > Resource based policy. If no resource policy exists then you need to manually add a policy to allow EventBridge to invoke it. For this click on Resource based policy > Policy statements > Add permissions. * policy statement = AWS service * service = EventBridge * statement id = eventbridge-1000 (or any unique id) * principal = events.amazonaws.com * source ARN = arn:aws:events:us-east-1:801598032724:rule/datasync-trigger (arn for eventbridge event)
Verify event and datasync task execution
- We have configured eventbridge to fire an event after every 5 min we can verify it from eventbrige monitoring tab and its cloudwatch logs.
- Lambda function invocations can be verified from its cloudwatch logs
- Datasync task execution status can be verified from its history tab and cloudwatch logs.